Since a seminal Bing paper, using LLMs as relevance judges has appealed to many search teams.
In this article, I’ll walk through how I setup a local LLM to be a pairwise labeler, that tells us which two search results are more relevant for a query. This will let us have an LLM ‘clippy’📎 in the loop to compare two search relevance algorithms. I’ll push the labeler to be confident and precise, letting it say “I dont know”.
Importantly, I’ll use a local LLM - Qwen 2.5 from Alibaba. My example repo sets all this up, letting you do this all for free.
Why use LLMs to label results? Well our typical sources for labeling search results are pretty annoying. We haev two primary sources:
-
Live humans - Asking our friends, colleagues, or outside firms to label results as relevant / not. Unfortunately humans must be heavily coached to produce consistent ratings. Its a lot of tedious work, and not always consistent.
-
Clickstream data - Mining clicks and conversions for labels using statistical models. To do this, we need a lot of traffic on one query. We further need to account for the most pernicous problem of all - presentation bias - that humans only click on what they can see
Both cases struggle with a limited universe of labels, each with their own biases and issues.
If we could generate labels on the fly, we could have an Oracle in the loop as we improve search to ask “Which of these is most relevant?”. Comparing two algorithms results on the fly, flagging issues and highlighting improvements. That’s exactly what I’m after.
Bootstrapping an LLM Relevance Oracle – traditional labels still needed
While LLM labeling takes pressure off your traditional labeling efforts (humans/clickstream), it doesn’t replace them. It instead becomes the basis for building an LLM Oracle.
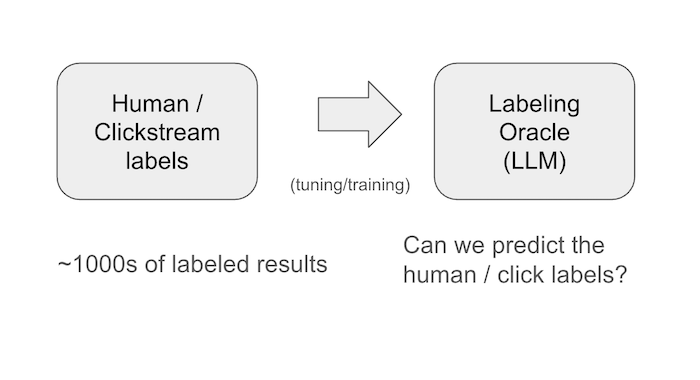
Like a lot of things, it’s not just about reducing cost. It’s about sometimes ramping up cost - at least in the short term - to gain more capabilities. It’s not about copy-pasting a prompt from a paper like Bing’s, but your own prompt engineering to get at your users + apps unique notion of relevance. You trust an LLM that agrees with reliable labels 95% of the time perhaps more than on 75% of the time.
Further, your search system is not static. You need to re-tune and re-evaluate periodically as use-cases and content evolves
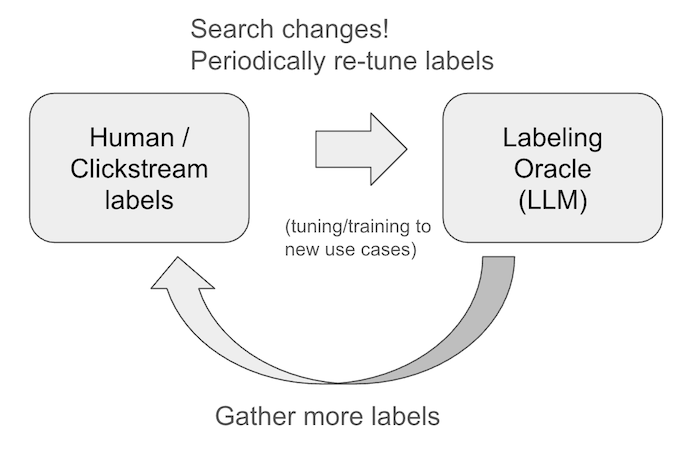
But with regular care and feeding, an LLM Oracle you can trust will give your day-to-day search relevance efforts a massive turbocharge.
Experimental setup
I’m going to use an open furniture e-commerce dataset from Wayfair - WANDS. WANDS labels results 0 (least relevant) to 2 (most relevant) for a query. I can then give the LLM the query, and some product metadata, craft a prompt, and essentially ask “which of these is most relevant?”. To test my labeler, I can measure agreement to which human raters see as more relevant.
I’m going to us a local LLM that runs fairly well on Apple Silicon - Qwen 2.5. There’s a convenient way to just pip install on Apple Silicon with the mlx library and run through a thousand of pairwise evaluations in a few minutes. Then you can see the code I’m using to explore different prompts here. Follow the README to setup and run.
Always start with a stupid baseline
What’s the dumbest thing that could possibly work? Our first attempt is fairly idiotic - here’s just the product name, Mr. LLM, which is more relevant?
Query: salon chair
Product LHS: adrushan genuine leather conference chair
Product RHS: 4 pieces patio furniture set outdoor garden patio conversation sets poolside lawn chairs with glass coffee table porch furniture
Respond with just 'LHS' or 'RHS'
Running with poetry run python pairwise.py --N 1000 --eval-fn name
After this script tries out 1000 pairs, you’ll see -
Precision: 75.08%
This isn’t a bad start. It agrees 75% of the time. Better than I might expect. But I’m not sure I’d bet my search career on it yet, as 25% of the time, it gives the wrong preference.
Allowing ‘I don’t know’ - higher precision, lower recall
When you look at failure modes, you see a lot of cases where the LLM simply doesn’t have much information to go on. But we forced a choice of LHS or RHS.
Take the example below, where both products are ‘coffee table’ yet humans would label one as more relevant than the other. We need more information.
Query: entrance table
Product LHS: aleah coffee table
Product RHS: marta coffee table
Respond with just 'LHS' or 'RHS'<|end|>
*** Output ***
RHS<|end|>
We can go down the path of cramming in more context/fields. But I a different tack first is important to take first. Let’s let the LLM tell us “I dont know” and default to assume it works from limited information. Even WITH all the fields, there may still not be enough to tell why users prefer one product over another.
Importantyl, I need the LLM to be really confident when it flags something. I want to focus on precision - getting the answer right - rather than recall - trying to give everything an answer. I can use my brain or get human labels for ambiguous cases. I may be able to trust in A/B testing to help also answer which algorithm produces the best results.
So next step, let’s allow usage of the product’s name, but allow it to say “Neither”. In fact encourage it, unless there’s compelling evidence:
Neither product is more relevant to the query, unless given compelling evidence.
Which of these product names (if either) is more relevant to the furniture e-commerce search query:
Query: entrance table
Product LHS name: aleah coffee table
(remaining product attributes omited)
Or
Product RHS name: marta coffee table
(remaining product attributes omited)
Or
Neither / Need more product attributes
Only respond 'LHS' or 'RHS' if you are confident in your decision
Respond with just 'LHS - I am confident', 'RHS - I am confident', or 'Neither - not confident'
with no other text. Respond 'Neither' if not enough evidence.
With this change, we improve our precision of what’s labeled, but we reduce the overall recall:
poetry run python -m local_llm_judge.main --verbose --eval-fn name_allow_neither
Precision: 85.38% | Recall: 17.10% (N=1000)
17% of our results recieved labels, of those 85% agreed with the human labelers. When we zero in, we see:
- Mostly: Cases where the product name is misleading (a ‘kids desk’ that appears to not actually be a kids desk)
- Some Mistakes - cases where the labeler should said “Neither”
Examine the results yourself and see what comes out for you.
More fields into the context:
We can uses this template to ask about pairwise relevance with other data in the corpus, with description, category (where it sits in a taxonomy), and class:
poetry run python -m local_llm_judge.main --verbose --eval-fn class_allow_neither
poetry run python -m local_llm_judge.main --verbose --eval-fn category_allow_neither
poetry run python -m local_llm_judge.main --verbose --eval-fn desc_allow_neither
(And images given a multimodal model)
Respectively resulting in:
Precision: 87.01% | Recall: 17.70% (N=1000)
Precision: 85.71% | Recall: 18.20% (N=1000)
Precision: 79.21% | Recall: 10.10% (N=1000)
(This gives us also a hint on the importance of each field in predicting relevance.)
Now we have a choice. We could
- Make an uber prompt with the full product info and ask for pairwise relevance. Try to improve precision and recall here. Hopefully get good at both!
- Just use what we’ve built so far. Keep field-prompts separate and alert our search tuner when they have a potential issue for deeper inspection (hey this name is out of whack!)
The first option - one true LLM Relevance Oracle - will require more tuning and careful work/measurement. It’s mistakes will be trickier to debug as it’ll take a little probing to interpret “why” the LLM made a decision. We will need to ensure it can handle the amount of context we’re giving the product, especially for a local LLM.
The second option, however, would just be a safety net to tell us when one field “looks out of whack” as a way to guide qualitative tuning. Like “oh this name looks weird for this query”. Such a tool would compare pairs of results between two algorithms and flag the algorithm’s pairwise preference in given fields, summarizing what’s misleading. It’s doubtful any approach would get 100% precision (sometimes fields are weird) but it may also help us find data issues or places where cleaning up a misleading name or classification could help.
I feel the second option would be a great first step for most search teams. No matter how much we say we’re 100% data driven, in reality measuring two search algorithms has a lot of LGTM and eyeballing side-by-side tools. Flagging the evaluators attention to “hey this is weird” could be invaluable for data and search quality.
What would be next?
(Next post in series – here )
This is a good first foray into pairwise relevance labeling given a few fields. We use a local LLM to save cost. As a follow on, I’m going to consider:
- Ensemble - Trying out an ensemble of the “allow_neither” strategies above, letting each field have a vote on relevance labeling, and considering an inconsistent response as “Neither”
- Uber Prompt - Continuing to think about an uber-prompt that uses all fields to make a pairwise relevance decision
- Chain of thought - Consider some chain-of-thought style approaches to get the LLM to explain its rationale in a step by step fashion, letting us understand its thought process, perhaps to enable combining fields into a single prompt.
I encourage you to take the repo and implement your own approach to see what works best. Importantly, you also ought to see what works best for your data and labels - search is massively diverse field with a huge variety of expectations when it comes to relevance.
But I think with Local LLMs we’re at an inflection point. Local LLMs like Qwen can rate 1000 pairs in a few minutes. This opens up the relevance sandboxaccelelrating search tuning iterations. We can’t replace traditional raters, as search evolves, and we need to tune our prompts. But with less manual work needed, it could be a step towards democratizing the search space, letting everyone participate, not just those that can afford raters. I trust we’re going to see a tremendous amount of innovation in this area even over the next few months.
Please get in touch to give me feedback or schedule coffee if you want to chat more about what’s worked well for you!
Enjoy softwaredoug in training course form!
Starting May 18!
Signup here - http://maven.com/softwaredoug/cheat-at-search I hope you join me at Cheat at Search with Agents to learn use agents in search. build better RAG and use LLMs in query understanding.
I hope you join me at Cheat at Search with Agents to learn use agents in search. build better RAG and use LLMs in query understanding.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky