How is search implemented where you work? Probably as a complex set of capabilities on top of retrieval. Our search APIs understand queries, call backend search systems, and finally rerank results.
But if we had an agent in the loop, would we need all that? Could we replace search backends with an agent? After all, an agent understands user requests, calls retrieval tools, and evaluates relevance on its own. We see ChatGPT do this all the time, why can’t our search bar?
In other words, if you give a basic BM25 backend to an agent, could it take the Search API’s job?
Surprisingly good results with simple tool usage
Well I’ve measured initial findings (a bit deeper than in the past). I gave agents basic search tools and got the popcorn out to watch.
On Amazon ESCI, we see increasing performance with slightly better retrievers + LLMs.
First, we start with a bm25+e5_embedding baseline. They achieve 0.289/0.314 NDCG respectively.
Then we measure three agentic experiments. Each with GPT-5-mini driving different combinations of search tools. We see an agent with e5 embeddings get 0.359 and with BM25 0.385. With both we get 0.410.
GPT-5 with both tools gets an NDCG of 0.453.
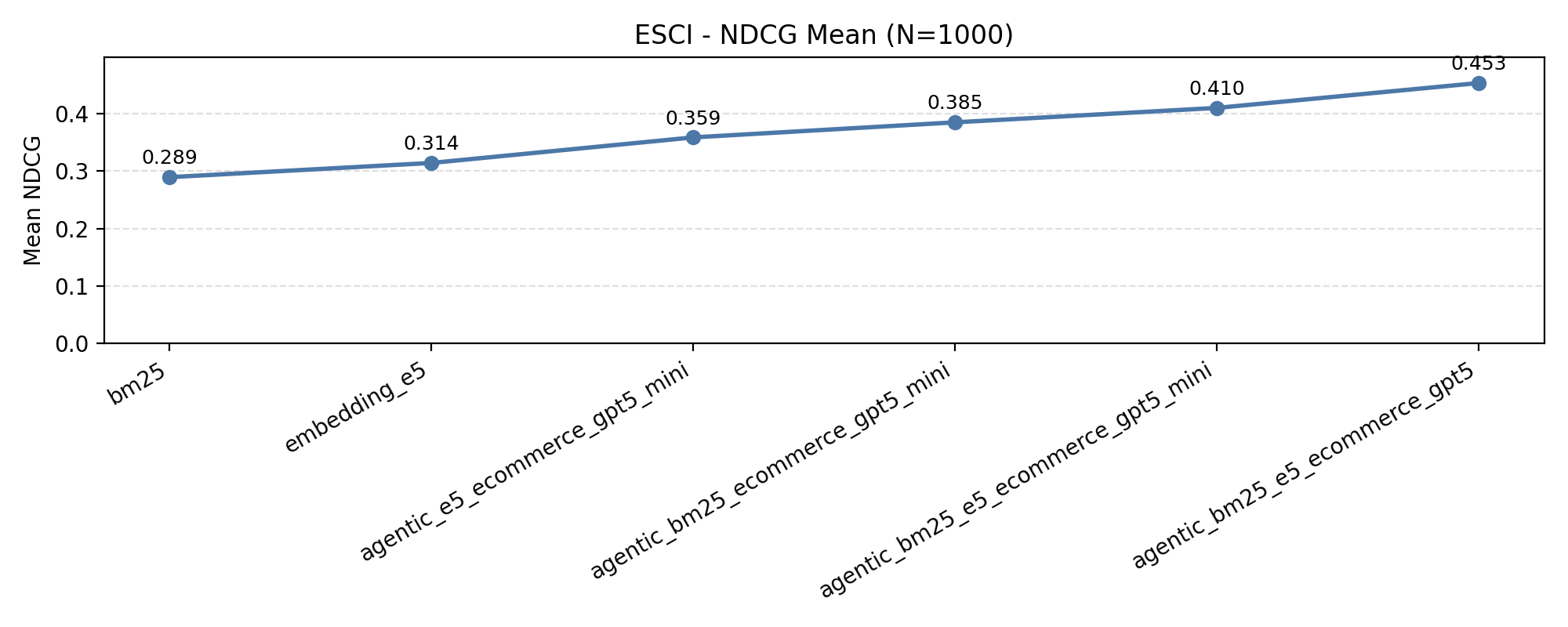
What’s amazing about this? I’ve barely lifted a finger. I just set up a stock LLM with some search tools. Nothing here has been fit to my data. A 0.289→0.453 jump in quality depends only on model quality + simple retrievers.
If an agent could be fast enough, is there a future here we build search with agents and not APIs? A world where agents reason about queries to show users the best results?
But, agents call search approximately… once?
What kind of ingenious strategies are these agents employing? It turns out, for the most part, they call each search tool roughly once:

When you look at reasoning traces, you see the agent interpret the search, issue a single query, retrieve up to the max of 20 results, then rank them.
Occasionally, very rarely, with just BM25, you’ll see two simultaneous searches. For example, “PVC coupler” shows first a BM25 search for “pvc coupler”, the agent, disappointed with results, issues a follow up query (PVC pipe coupler):
Calling search_bm25 with args keywords='pvc coupler' top_k=20
**Searching for PVC couplers** I noticed that the search results mainly
returned RJ45 couplers, which are for network cables, not what the user likely
meant. They’re probably asking about PVC pipe couplers used in plumbing. The
current search tool isn't yielding entries for PVC pipe couplers specifically. I
saw mentions of PVC in descriptions, but it’s clearer to use broader keywords to
refine my search. I need to focus on terms like "PVC pipe coupler" or "PVC
coupling" to get better results, so I'll try that next.
Calling search_bm25 with args keywords='PVC pipe coupler' top_k=20
You also see cases where the agent uses BM25 to issue two queries simultaneously, anticipating inconsistent results:
Calling search_bm25 with args keywords='AN10 oil catch can no filter' top_k=20
Calling search_bm25 with args keywords='AN10 oil catch can without breather filter' top_k=20
There’s something about keyword search, it seems, that nudges the agent to try more queries. The agent can interpret results, understand why they didn’t match, and take next steps. Keyword search has cause-and-effect (keywords matched / or didn’t). Agents can react to that and improve.
Encouraging exploration improves further
I want agent exploration to be the norm, not the exception.
We haven’t changed a thing about the harness. We could steer agents to search more effectively. What happens with a few small changes to our setup:
- Require more tool calls - we ask the agent to keep trying if its made fewer than the required number of tool calls (ie 4). We say something encouraging like “wow these are great, but I bet you can do better!”
- Require the agent use diverse retrieval queries - to ensure the agent truly explores, we reject queries too similar to those issued by the agent previously for this search.
Within the GPT-5-mini examples, we see incremental improvements.
| strategy | model | mean | median |
|---|---|---|---|
| Two tools | gpt-5-mini | 0.4101 | 0.3743 |
| Require 4 calls, disallow duplicates | gpt-5-mini | 0.4290 | 0.3948 |
| Require 4 calls, disallow queries > 0.9 sim to past queries | gpt-5-mini | 0.4308 | 0.4258 |
That’s nice, it approaches the GPT-5 benchmark from before, but with a smaller model. Albeit with more tool calls.
What I haven’t yet tested are retrieval tools rich with affordances - bits of metadata making it easy to focus on important parts of the corpus. A category filter. A search tool for recent information. And so on.
What about agentic search models (ie SID-1)?
Another possibility comes from new agentic search models. Teams like SID train models that act as drop-in replacements for your RAG stack. Setup some retrieval tools, and a model like SID-1 will figure out how to surface relevant results.
Why a dedicated agentic search model? Frontier lab LLMs think of “search” as web search. So they issue a query once, trust the results, and move on. That’s valuable because they’re reasoning about the user’s problem - not search relevance.
But a model like SID-1 reasons about relevance realistically. Our companies build less sophisticated retrievers. SID-1 knows that. So it takes care to explore thoughtfully, reason about the results, and retry. As a self-hosted subagent, focused only on retrieving results that satisfy the search, SID-1 leaves the main LLM focused on the user’s task.
To be smaller+faster+good, they must focus. One wonders if we’ll have agentic search LLMs tailored to different domains. One good at e-commerce. Another at job search. Another good at document retrieval, etc. Or search teams fine tuning agentic search models for their domain?
The tradeoffs look like embedding models: the training data dictates the models sweet spot. Move too far away, and suddenly get suboptimal results.
“Finding things” different than Deep Research
Where does this agentic search nirvana break down? So far we’ve focused on finding things (products, jobs, etc). But what about information the agent doesn’t have? That’s fundamentally a different problem.
Change to MSMarco passages dataset. There’s no improvement by letting an agent drive tools. You can’t beat the embedding model.
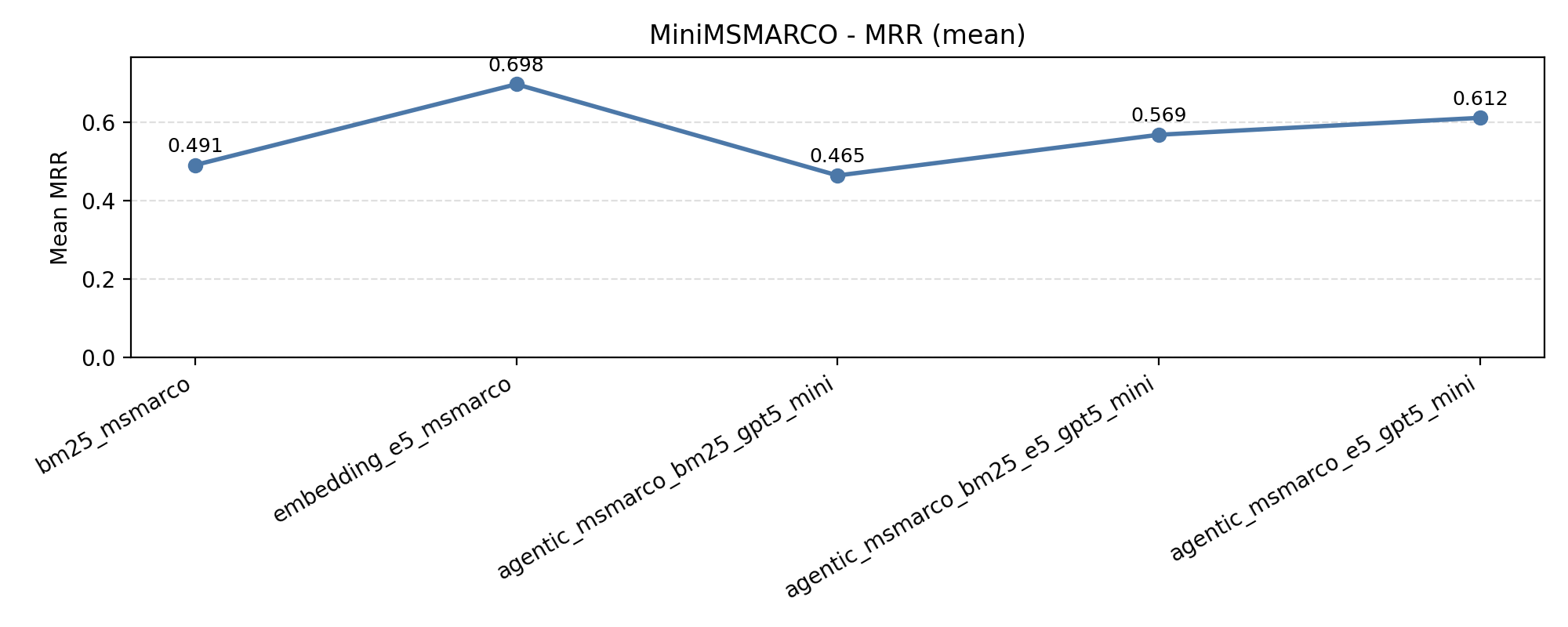
This embedding model has MSMarco in its training set. So the retriever knows best. The LLM can’t evaluate what it doesn’t know. If it knew what information was correct, it wouldn’t need search!
That’s a difference between two worlds of agentic search. One where an agent helps us find things. Another where the agent needs our help to learn. This latter case is where the traditional search stack still thrives.
I’d call this last approach “Deep Research” - while what I’ve been doing as “agentic search”. As they currently exist, LLMs have gaps about their knowledge, and nothing I’ve talked about would be suitable for compensating for the LLMs lack of knowledge.
Enjoy softwaredoug in training course form!
Starting May 18!
Signup here - http://maven.com/softwaredoug/cheat-at-search I hope you join me at Cheat at Search with Agents to learn use agents in search. build better RAG and use LLMs in query understanding.
I hope you join me at Cheat at Search with Agents to learn use agents in search. build better RAG and use LLMs in query understanding.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky