In my previous article, I hypothesized reasoning agents work best with simple search tools. In agentic search, we don’t build thick, complex search systems. Instead, I argued, we should build simple, easy-to-understand, and transparent ones like grep or basic keyword search. Agents iterate and learn: They sift through results, learn about the corpus, how retrieval works, and retry with what they’ve learned.
Well now I’ve taken time to measure what an agent can get away with in two datasets on (N=100) queries (all code here)
| Dataset | BM25 Baseline | BM25 Tool Driven by Agent (GPT-5) |
|---|---|---|
| WANDS (Wayfair Annotated Dataset) | 0.56 | 0.64 |
| ESCI (Amazon search dataset) | 0.30 | 0.39 |
Below, I’ll walk through what exactly I’m comparing, how it works, and give you the code breadcrumbs if you ever want to setup your own agentic search loop.
What are the variants?
BM25 Baseline
The BM25 baseline uses SearchArray to naively sum BM25 scores between snowball tokenized product name and description. I weigh product title / description scores based on a random search I did in the past (title is 2x description).
Boring :). But you’ll see more or less also what we also give the agent.
For each field:
def snowball_tokenizer(text):
...
# Ascii folding + punctuation to space
text = text.translate(all_trans).replace("'", " ")
split = text.lower().split()
return [stem_word(token)
for token in split]
self.index['title_snowball'] = SearchArray.index(corpus['title'],
snowball_tokenizer)
Then roughly, we search as follows:
def search(self, query, k=10):
"""Dumb baseline lexical search"""
tokenized = snowball_tokenizer(query)
bm25_scores = np.zeros(len(self.index))
for token in tokenized:
bm25_scores += \
(self.index['title_snowball'].array.score(token) * self.title_boost)
bm25_scores += self.index['description_snowball'].array.score(
token) * self.description_boost
...
Agent setup
The agentic loop sits at the core of the experiment. Below I outline the loop visually, followed by a code outline. If you’ve never written your own agentic loop to do a task, it’s very educational. If you have the means, I highly recommend it.
You can see below, we send in a prompt and specifications for tools the agent can use. We also share the structure we expect back (which I’ll discuss might influence the reasoning done):
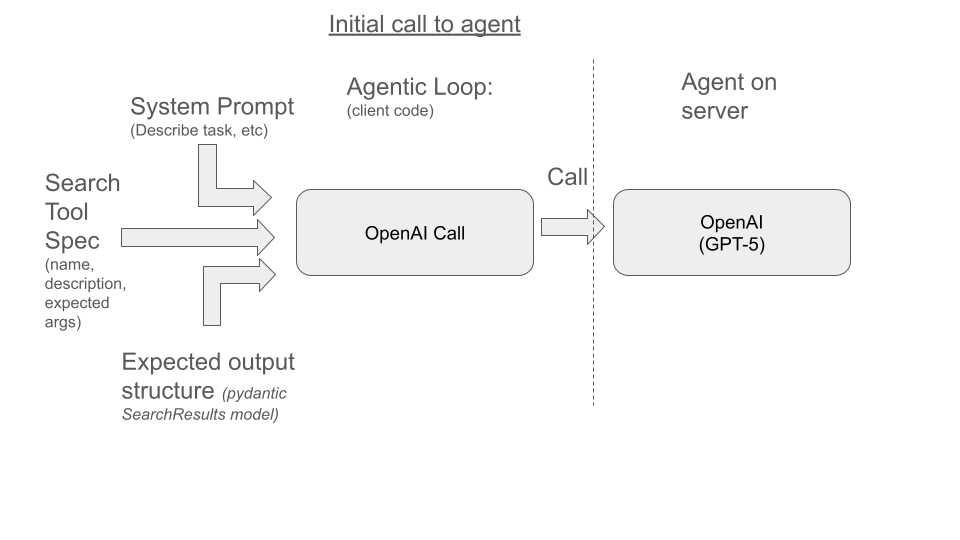
The agent will decide it needs to call tools only available on the client. To do so, it responds with a request for you to call a tool and package the tools output back to the agent:
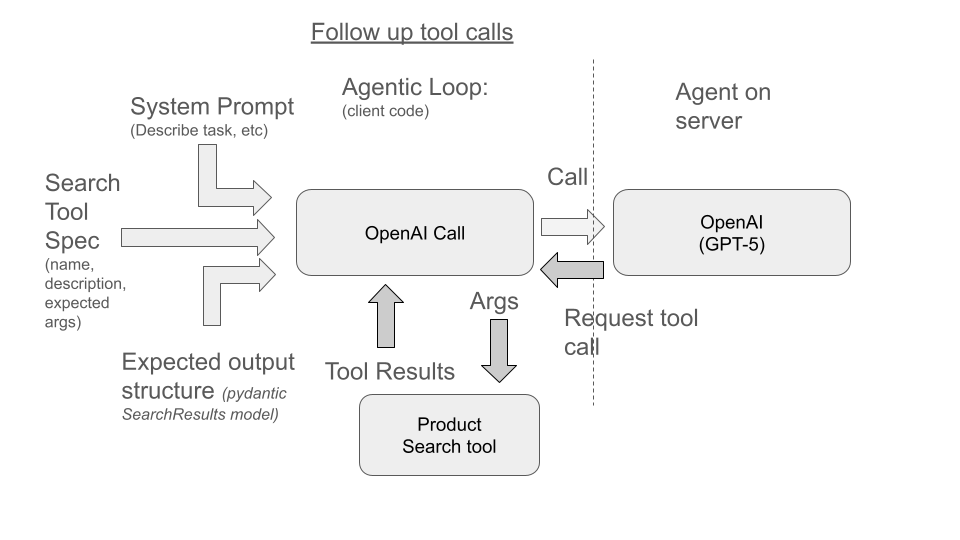
Once done, you’ll eventually find no more tool call requests, so you wrap up by returning the structured results:
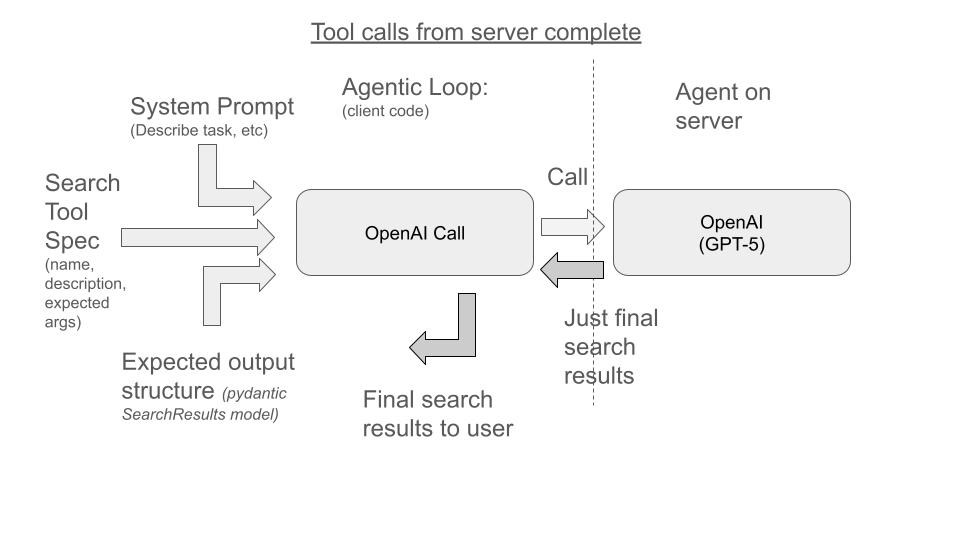
Or as summarized in the code below. We loop, calling the LLM, until no more tool calls are needed, at which point we return a structured output.
inputs = [
{"role": "system", "content": system_prompt},
]
tool_calls_found = True
while tool_calls_found:
# The initial call (diagram one)
# (But also subsequent calls with tool responses appended to `input`)
resp = self.openai.responses.parse(
model=self.model, # ie GPT-5
input=inputs, # All the user, tool, agent interactions so far
tools=tools, # Specifications of tools the agent can call
text_format=SearchResults # How the response should be formatted
)
inputs += resp.output
# Iterate, call tools, gather search results
# (The second figure above)
tool_calls_found = False
for item in resp.output:
if item.type == "function_call":
# Call function (ie search)
# Package up results back into
# `inputs` as a tool response
json_resp = # call tool, format response back to JSON
inputs.append({
"type": "function_call_output",
"call_id": item.call_id,
"output": json_resp,
})
# Return the structured response once the agent needs
# no additional tool calls
# (The third figure above)
return resp
I’m omitting a lot of pedantic pydantic plumbing to talk to Python functions, package up arguments and return values. But please explore the nitty-gritty code here.
With the outline out of the way, let’s explore the three main ingredients we plug into the agentic loop.
The prompt (+ few shot examples)
IANAPE (I Am Not A Prompt Engineer). So I’m expecting John Berryman to improve this prompt. But the prompt I pass in (here for ESCI)
You take user search queries and use a search tool to find products on the Amazon online store. Examples
of labeled query-product pairs are listed at the bottom of this prompt to help you
understand how we will evaluate your results.
Look at the search tools you have, their limitations, how they work, etc when forming your plan.
Finally return results to the user per the SearchResults schema, ranked best to worst.
Gather results until you have 10 best matches you can find. It's important to return at least 10.
It's very important you consider carefully the correct ranking as you'll be evaluated on
how close that is to the average shoppers ideal ranking.
Finally, some examples:
I give a sampling of 10 relevant query - products, irrelevant ones, and ones in-between, ie:
User Query: phresh probiotics for women
Product Name: Probiotic Pearls Acidophilus Once Daily Probiotic Supplement, 1 Billion Live Cultures, Survives Stomach Acid...
Product Description:
Human Label: Satisfactory
The search tool
Finally, we tell the agent about a search tool that looks like the BM25 baseline above. What can be hard to grasp: the agent doesn’t get a Python function. It gets told there exists a function called search_esci, that takes parameters keywords and tok_k. The agent gets the doc string as a description, and is told the return type the agent should expect. You can learn more from OpenAI’s tool spec)
def search_esci(keywords: str,
top_k: int = 5) -> List[Dict]:
"""
Search amazon products with the given keywords and filters
This is direct / naive BM25 keyword search with simple snowball stemming and whitespace tokenization.
Do not expect synonyms, compounding, decompounding, query understanding, or other NLP tricks.
Instead YOU need to reason about the user's intent and reformulate the query given the constraints.
Args:
keywords: The search query string.
top_k: The number of top results to return.
Returns:
Search results as a list of dictionaries with 'id', 'title', 'description', and 'score' keys.
"""
(BM25 code as above)
The response we get back (structured output)
Next the structure of the search results OpenAI should return back (via structured outputs). The requested outputs become part of the context. This can have an impact on how well the search works. Specifically, if I force GPT-5 to tell me why something is relevant, I believe (perhaps wrongly) it is forced to consider relevance more carefully. Perhaps this wisdom from ye olde manual chain-of-thought days no longer holds.
The SearchResults model, passed into text_format above is:
class SearchResults(BaseModel):
"""The results of a search query, ordered by relevance."""
query: str = Field(
..., description="The original search query passed by the user"
)
search_plans: list[SearchPlan] = Field(
..., description="The list of search plans used to retrieve results"
)
intent_explained: str = Field(
..., description="A summary of the user's intent based on the search query (especially as it relates to human judgments if available)"
)
results: list[SearchResult] = Field(
..., description="The list of search results"
)
I won’t go through each attribute, you can see the code here. But above you can see a bit what I mean. I ask the agent to explain the intent behind the user’s query. Does this help the agent reason about how to best satisfy the user’s request by forcing it to think about what the user wants? Or is it a waste of tokens and just lead to context rot?
Further experiments might show how much shrinking we could do :)
Future enhancements
I feel like this is just scratching the surface. Some additional enhancements I want to explore:
More structured filters in search tool
Originally, when I just focused on the WANDS (Wayfair) data, I had a tool that also allowed category filtering of search results before ranking. This seemed to help somewhat. But I haven’t gotten a chance to systematically investigate the benefit. As part of my course, I also have enriched the WANDS data with a lot of additional structured attributes that might benefit from filtering (color, room, etc).
Semantic cache training data query evals
ESCI has a large population of queries split between test / train. What if we simulated a case where we have reliable eval data on one set of queries (ie the training set) but no evals on another query set (the test queries). This case mirrors common situations in production. We might have a set of queries with extensive clickstream or other evaluation data. And another set we are blind on.
If we index the known eval queries into a vector index, when an unseen query arises, we can add a tool that looks up similar queries.
Tool memory
I mentioned in my original post the idea of storing the LLMs evaluation of specific tool calls. IE the search for “leather couch” worked well / did not work well to find relevant results for teh user’s “suede couch” query. I’d like to see whether adding tool memory helps / doesn’t help the agent take shortcuts. And whether subsequent iterations of the same query improve over time as the agent has deeper memory about the tools it used in the past for that user query.
Drafting on Tool Exhaust
Finally, if we build an agent that works very well, can we reuse the tool memory in online / non-agentic search? Could we lookup in that tool memory what keywords and filters tend to work well, then use that in classic search-bar style search?
Feedback? Ideas
This is all written in the spirit of experimentation, exploration, and happy failures 🙂 Please get in touch if you have feedback or ideas. Especially if you nee where I’ve screwed up!
Upcoming course: Build your own vector database

Want to understand what makes embedding retrieval fast, relevant, and useful in real AI systems? Join Build your own vector database and build the core pieces yourself, from embeddings and indexing to search and retrieval.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky