Recently I’ve been used agents to create search rankers. I can see that adding reasoning to a simple keyword search tool, can boost search relevance anywhere from 15-30%.
| Dataset | BM25 Baseline | BM25 Tool Driven by Agent (GPT-5) | Codegen (this article) |
|---|---|---|---|
| ESCI (Amazon search dataset) | 0.30 | 0.39 | 0.35 (10 rounds) |
Unfortunately, each query needs, on average 100K tokens. I can’t accept that cost and latency. Could we use reasoning to create a reranker without needing an agent for every query?
Code generation
What if an agent could express its search ranking process as generalizable, search reranking code? Then I only need to consume the 100K+ tokens once in a training process. Even cooler - I’ll have an optimized search function that works with a dumb keyword search backend, making it easy to deploy and scale.
It’s reasonable to be skeptical. Much of the power behind the LLM comes from the Ls (Large Language). Search isn’t an obvious, mechanical process. Instead the value we get out of search would be from the language-y features of the LLM that understands individual queries. Is there generalizable ranking function? Or is it all logic dependent on each query?
Let’s walk through an experiment. First I’ll just ask an LLM to generate code as the final output (the naive baseline). It won’t work consistently. Second I’ll create a workable, consistent optimization process that ignores overfitting. Third, I’ll work on getting rid of overfitting with appropriate guardrails.
(Notebooks for this article:
- Naive reranker code generator
- Code generator optimized for training NDCG (but overfit)
- Generalized reranker that uses guardrails to avoid overfitting )
If this interests you come to my agentic search class.
Trial 1 - dumping some code after an agentic process (baseline)
The first iteration on code generation built upon my previous blog post. I create an agent with a simple, keyword based search tool. You can search keywords, in a given field (title/description), filtered to a locale ESCI has us, jp (japanes), or es (spanish) products.
I tell the agent to “play with queries and derive good reranker code” as the final output. With this building block:
In: pd.DataFrame(search_esci("coffee mug", "product_name", "and"))
Output:
| index | id | title | description |
|---|---|---|---|
| 0 | B07KPT1826 | Baby groot jack daniel’s whiskey Mug Coffee Mug Gift Coffee Mug 11OZ Coffee Mug | |
| 1 | B07CQ5RNP1 | Funny Coffee Mug for Men and Women | If you’re looking for a funny coffee mug then you’ve come to the right place!… |
I expect code that takes multiple calls to search_esci and weaves together optimal results.
Below I outline the three main components to any agent:
- The tools available - using some helper code, python functions like the
search_escikeyword search tool described above - The prompt - the task to give the agent, how it should use its tools, etc (more on this in a bit)
- The expected output - here
GeneratedRerankerCodewhich outputs code and rationale behind it
# ---
# (3) The expected output
#. (basically the code and an explanation for debugging)
class GeneratedRerankerCode(BaseModel):
"""Python code that would best rerank search results."""
code: str = Field(..., description="Python code that would best rerank search results")
code_explanation: str = Field(..., description="Explanation of why the code will generalize beyond the examples")
# ---
# (2) The tools used by the agent
# search_esci has the signature:
# def search_esci(keywords: str,
# field_to_search: Literal['product_name', 'product_description'],
# operator: Literal['and', 'or'],
# locale: Literal['es', 'us', 'jp'] = 'us',
# top_k: int = 5) -> List[Dict]:
tools = [search_esci]
# ---
# Setup agentic lop w/ prompt, tools, expected output
agent = OpenAIAgent(tools=tools,
model="openai/gpt-5",
system_prompt=system_prompt,
response_model=GeneratedRerankerCode)
# ---
# Run agent (loop making tool calls from agent -> search_esci until done)
# save code. (See below)
resp: GeneratedRerankerCode = agent.loop() #< AGENTIC LOOP
# ---
# Save code
with open("rerank_esci.py", "w") as f:
f.write(resp.code)
If you’re new to agents, behind the loop method is this psuedocode. The agentic loop iterates through any tool calls, returns the results, until the LLM is done:
# The agentic loop
inputs = system_prompt
# Iterate while LLM wants to make tools
while tool_calls:
# Call OpenAI (either first call, or subsequent call with tool outputs)
resp = call_open_ai(inputs, tools)
inputs += resp.output
# Execute tool calls and save output
# (ie call search_esci and package up search results for GPT-5)
for tool_call in resp.output.tool_calls:
tool_output = tools[tool_call.name](tool_call.params) # ie search_esci
inputs += tool_output # ie Package up search results to send back
# Done making tools, return output
return resp
Finally the system prompt includes:
- Instructions describing aspects of the problem
- A set of queries + search results to help the LLM understand what the data looks like
Generate python code using 'search_esci' as a function (the tool here). Assume search_esci has the python
signature as defined in tools.
Issue test queries using search_esci to see how it works, what its limitations are, etc before formulating
your plan. Create novel queries to test the tool, see how well it works, and iterate to improve your code and
reranker.
Then generate a *generalized* reranker as a function of search_esci, call this function 'rerank_esci', it should
return a list of product IDs in the order you think best matches the query. It should take as a parameter the 'search_esci'
tool to help (as the tool will be injected from outside).
It's very important you consider carefully the correct ranking as you'll be evaluated on
how close that is to the average shoppers ideal ranking.
Examples of labeled query-product pairs are listed at the bottom of this prompt to help you
understand how we will evaluate your results.
Your goal is to generate a ranker that doesn't need to have specific query terms mentioned in the code,
but can figure out the intent of the query and use the search tool to find the best products. You can use general, broad categories,
stopwords, concepts, etc, but think beyond the queries you're presented
In other words, overfitting is bad!!!
Generate valid python. Double check your code.
Finally, some examples:
User Query: kitchenaid bowls
Title: KitchenAid 6-qt. Mixing Bowl with Ergonomic Handle.
Human Label: 🤩 (grade: 3)
...
Notice the goals here:
- An emphasis on generalizing and not overfitting. We want to avoid “if query == “shoes” then
” - Encouraging producing correct ranking
- Defining a reranker function signature that takes as parameters
search_esci(the search function above) and the search query. It returns a ranked list of product_ids.
Once done, we can then use our brand spanking new reranker, to execute the generated code:
from rerank_esci import rerank_esci
importlib.reload(importlib.import_module("rerank_esci"))
product_ids = rerank_esci(search_esci, query)[:k]
Does it work? Inconsistently.
If we do this over 100 test queries in ESCI, we get an NDCG of 0.33
Woohoo, it got better? 🙂 Actually wait a tick…
If I re-run over 100 different queries than what are in the training set, I get 0.24 and finally, just rerunning on the same 100 usually gives me an improvement, but the NDCG can range randomly from 0.28 to 0.34 .
Trial 2 - Wiring in clear causality between edits and measurement
So that didn’t work. Let’s work on a second iteration.
With no other forms of feedback, I realized the agent will focus on valid Python code and call it a day. The agent needs more feedback on whether its changes led to good search - ie “this query improved, this got worse” etc. Then it can iterate and reason how to improve the code.
But to gain meaningful insight from granular feedback, the agent can’t make giant, sweeping changes. Just like a human, the agent learns more from incremental changes. Change a few lines, see the impact, iterate, improve. A giant, slow, big “waterfall” event at the end, leading to amazing success or catastrophe won’t teach you much about your search (hint to many search organizations out there - this applies to you too!).
To put it visually, agents need to propose granular changes, measure granular impact (good or bad), establish causality, repeat, as seen below:
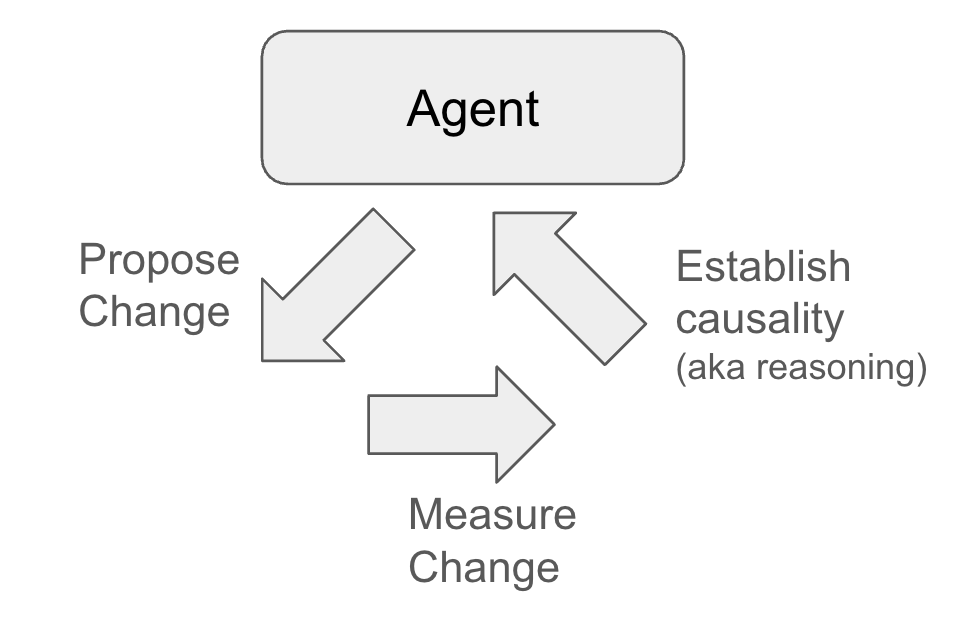
So I changed my approach.
I start with a dummy reranker code, that the agent can make incremental changes to:
original_source = """
def rerank_esci(search_esci, query):
docs = search_esci(keywords=query, field_to_search='product_name', operator='and', locale='us', top_k=10)
return [doc['id'] for doc in docs]
"""
with open("rerank_esci.py", "w") as f:
f.write(original_source)
To keep it simple for now, and to confirm my assumptions that this would work, I gave up eliminating overfitting (for now), expecting search to get better for the 100 queries with no expectation search would work well beyond them.
Let’s walk through the agentic loop and the tools involved.
# Create system prompt with sample query / product judgments
prompt = build_few_shot_prompt(seed=42, num_queries=4, num_per_query=4)
# ---
# System prompt
# Add initial reranker code to system prompt for system to improve
prompt += f"""
Reranker code to improve:
{code}
"""
tools = [# -------
# Tools to propose changes
apply_patch, # Edit the reranker with a patch
revert_reranker # Restore the reranker to the last version
# -------
# Tools to inspect changes
search_esci, # The raw search tool (from earlier)
run_reranker, # Run on one query (optionally label results)
run_evals, # Run on test set, getting per-query NDCG and mean NDCG
]
search_client = OpenAIAgent(tools=tools,
model="openai/gpt-5",
system_prompt=prompt,
response_model=FinalMessage)
resp: FinalMessage = search_client.loop()
I’ll go through the general functionality of the tools, if you want to deep dive into the implementation it’s all here.
Editing tooling
Remember, I want the agent to be incremental and easy to reason about. That’s how I’ve setup apply_patch. This would be similar to how a coding agent would make changes, proposing individual edits, then having an opportunity to measure the success of those edits.
To give you a sense of what the coding agent does, I’ll share the signature:
def apply_patch(edit: Edit, backup=True) -> EditResult:
"""Apply an edit to reranker code.
Also backs up the reranker code before applying the patch, which
you can restore with `restore_reranker`
"""
...
(Note in my setup, the agent sees the doc strings as tool descriptions)
It takes a single Edit proposed by the agent. This is a kind of “search and replace”: find anchor and make the proposed change until you find block_until
class Edit(BaseModel):
"""A single edit to apply to the reranker code."""
anchor: str = Field(..., description="The anchor text to identify where the patch should be applied.")
block_until: str = Field(..., description="The end of the block of text which the patch should be applied. Do not leave blank.")
action: Literal['insert_after', 'replace', 'delete'] = Field(..., description="The action to perform: insert_after, replace, or delete.")
text: str = Field(..., description="The text to insert or replace with. Ignored for delete action.")
intention: str = Field(..., description="Why are you making this edit.")
test_queries: List[str] = Field(..., description="A list of test queries to validate the reranker after applying edits.")
If the edit produces runnable code, test queries return sensible results, and the model doesn’t have any obvious errors rerank_esci.py is modified. The agent can now eval.
I also provide a simple revert_changes so an agent can hit the “undo button” should catastrophe strike. If evals prove the change disastrous, it can hit the undo button.
Eval tooling
To reason about a change, we need the agent to get different perspectives on the problem. So I offer two primary eval tools. These mirror eval tools a human would use to analyze a search relevance problem.
First get a table of which queries had their NDCG improve / decline
class EvalResults(BaseModel):
"""The result of evaluating the reranker on ground truth search judgments."""
query_ndcgs: List[Dict] = Field(..., description="Per query search quality (as NDCGs)")
mean_ndcg: float = Field(..., description="The mean NDCG across all queries.")
def run_evals() -> EvalResults:
...
Finally, run a single query, get the reranker’s current 10, and optionally label them if the document appears labeled for this query.
def run_reranker(query, label=False) -> Union[List[Dict], str]:
"""Run the reranker. Returns a list of products or an error message.
Set label=True to return human labels with product details (only use if query is from judgments).
"""
System prompt
Finally, the prompt itself is really just telling the agent about the task, and a bit about the tools.
system_few_shot_prompt = """
Your task is to look at the data and improve the reranker code so that it returns more relevant results
Edit the reranker python module using apply_patch method.
You can run the reranker using the 'run_reranker' function, which takes a query and returns ranked, matching
products.
You can evaluate the reranker using the 'run_evals' function, which returns NDCG scores for all queries and mean NDCG. Your goal is to
increase mean NDCG.
If NDCG decreases, restore the reranker to its original state using the 'restore_reranker' function. This
will return the source code of the last reranker (pre patch) as a reset.
Experiment with the current reranker by calling it with test queries. Improve the reranker based on the behavior you observe. Make edits and test while you edit.
Your code MUST have a function rerank_esci. It takes as parameters search_esci function and a query string. It
returns a list of product IDs in the order you think best matches the query.
Here are some examples of user queries, product titles, and human labels (Relevant, Partially Relevant, Irrelevant) that
you are ranking:
...
"""
It also appends the starting code (as stated above)
# ---
# System prompt
# Add initial reranker code to system prompt for system to improve
prompt += f"""
Reranker code to improve:
{code}
"""
One feature of this process, I can run rounds of the agent. With each round working on the code output from the previous round.
Testing
On 100 queries, I see NDCG gradually improve on my 100 queries. Which is good! It means I can run my agent and see code changes consistently turn into NDCG improvements.
Codegen NDCG: 0.3540408771556313
Baseline NDCG: 0.309476454990613
Round 0 NDCG: 0.27278591751020964
Round 1 NDCG: 0.34060909284456237
Round 2 NDCG: 0.34060909284456237
Round 3 NDCG: 0.3414165715059903
Round 4 NDCG: 0.3474432423016626
Round 5 NDCG: 0.3474432423016626
Round 6 NDCG: 0.35034528809491555
Round 7 NDCG: 0.34693111657344144
Round 8 NDCG: 0.3481568506009639
Round 9 NDCG: 0.3540408771556313
Trial 3 - trust but verify with guardrails
OK everything we’ve done so far is next to useless. To really make progress, we have to make a reranker that generalizes across multiple queries.
To avoid overfitting, initially I nagged and harangued the agent via prompts to not overfit. That works as well as lecturing a five year-old why they should eat their vegetables. Instead of a lecture, turns out what works is not giving dessert if they don’t eat their veggies!
In other words, I moved to outright rejecting code changes that didn’t fit my high expectations. I began using more guardrails in apply_patch itself before accepting code.
I rejected code that violated these constraints:
- Small changes - Keeping the code changes incremental (each change less than 10 lines, 120 columns).
- Code that ‘looks’ overfit - Avoiding code that mentions explicit queries (each change is checked with a second LLM that confirms not being overfit)
- Code that is overfit - Avoiding changes that don’t improve NDCG on a holdout set different from the training set the LLM has access to
Couple this with prompt changes to tell the agent why it should listen to me, the wise parent, and we begin to see the expected generalizations. We also return verbose messages to help the agent correct its mistakes.
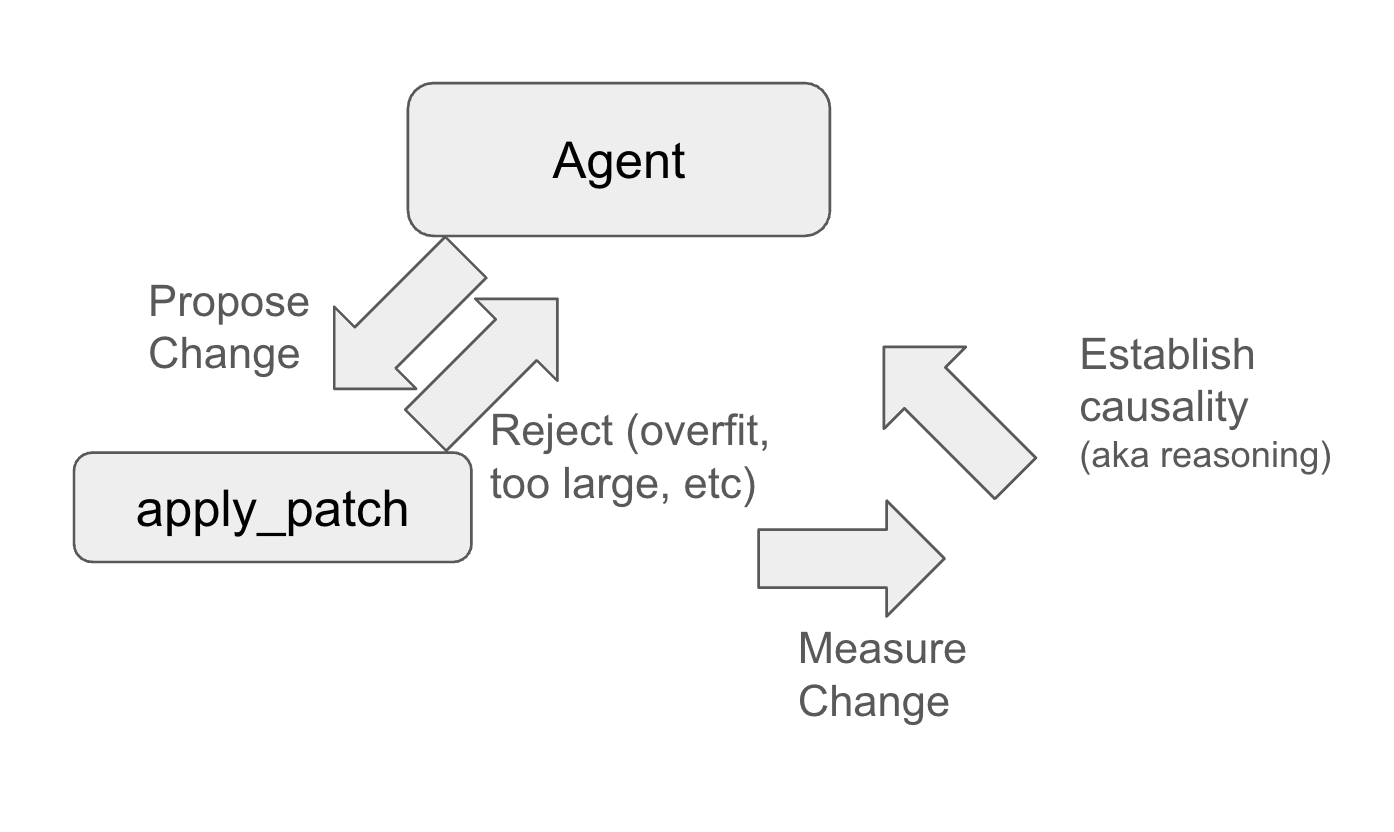
Guardrails aren’t complex. Already apply_patch returns error messages. And we add some new functions to give new error messages.
We now have three sets of queries:
- Training Set - the 100 queries we’ve been using. These are queries the agent’s directly sees. The agent’s eval tools use these, and can inspect these query’s NDCGs and results
- Validation Set - New! - this is what’s used by
apply_patchto potentially reject changes as overfit. The agent only sees the mean NDCG of the entire set afterapply_patchfails, but not specific queries. - Test Set - New! - what we use to evaluate the resulting code. The most “held out” set of queries the agent never sees.
The results show promise, on the test set, we see NDCG go from 0.28 → 0.35. So a generalized ranker with about an 18% increase. Nice!
Baseline NDCG: 0.309476454990613
Round 0 NDCG: 0.2862769272456307
Round 1 NDCG: 0.3316730214643777
Round 2 NDCG: 0.33533106238024274
Round 3 NDCG: 0.34448293881974956
Round 4 NDCG: 0.34416319894710357
Round 5 NDCG: 0.3470300191611667
Round 6 NDCG: 0.3479435616544409
Round 7 NDCG: 0.34835233321075343
Round 8 NDCG: 0.3473998877426597
Round 9 NDCG: 0.35049160973155014
Very cool! And a good place to leave today’s work. We can indeed build a generalized reranker with a modest improvement to search metrics.
Big takeaways
Some high level lessons I learned from this process I think anyone could take into building agents:
- Build iterative and interpretable feedback loops - incremental changes with clear feedback on success/failure help the agent learn better than giant waterfall, “big bang” changes
- Enforce consequences for the agent - in my case, not accepting code when expectations are not back, is a stark feedback signal to the agent to change course. And it works! Treat the prompt as an optimization - to help it avoid wasting tokens on the mistake
- Agents want to overfit - build very strong generalization enforcement when accepting outputs from the process. Reject those changes, and ask the agent to try again.
Ongoing challenges
While this approach will help you develop reranking code, it still has a few challenges.
The big problem: as each round builds on the code of the last round, it can tend to build more and more complex code that juuust eeks out an improvement to the validation NDCG. This tends to create some degree of plateauing on test / overfitting to validation. If I keep running the 3rd notebook past the 10th round, subsequent rounds of above end up degrading test NDCG:
Round 10 NDCG: 0.35049160973155014
Round 11 NDCG: 0.35149882903981267
Round 12 NDCG: 0.3512228308204463
Round 13 NDCG: 0.34849594518745036
Round 14 NDCG: 0.3424425648866782
Round 15 NDCG: 0.3424425648866782
Round 16 NDCG: 0.34037644918419885
Round 17 NDCG: 0.3419466971180831
Would a genetic approach help here? Something that took different promising candidates and tried to combine them? Would that somehow take the best of both? Or simply end up concatt’ing them?
Should I add a margin to the validation NDCG guardrail? I would force the agent to improve NDCG on validation set by at least a constant amount. IE what if it has to improve 0.05 otherwise changes would be rejected? That would mean increasing only allowing through changes that significantly helped NDCG and removing those that didn’t. This might be counterproductive.
Should I create a tool to let the agent see raw search judgments of any query it wants? I had done this initially, but my fear was creating extremely overfit code. But perhaps my guardrails suffice to protect against that happening?
Should I create an additional search primitive besides keyword search? Would this help get out of whatever local maxima the agent seems stuck on?
Second, like a 5 year old, the agent does its best to game the rules. For example, I added the code length / column width guardrail co encourage the agent to make incremental changes. However, it tends to make minified code, such as:
def rerank_esci(search_esci, query):
q=query.strip(); ql=q.lower()
jp=any('\u3040'<=c<='\u30ff' or '\u4e00'<=c<='\u9fff' for c in ql)
es={'de','la','el','y','para','con','en','los','las'} & set(ql.split()); lc='jp' if jp else ('es' if es else 'us')
S=lambda f,op: search_esci(keywords=q, field_to_search=f, operator=op, locale=lc, top_k=50)
# Improve ES locale detection by checking for accented Spanish characters
acc = any(c in 'áéíóúüñ¿¡' for c in ql)
if not jp and acc:
lc = 'es'
...
Finally, I have not compacted any of the inputs on each round. I wonder if compacting the NDCG deltas to just the changed queries, for example, would focus the LLMs attention more clearly on what queries to investigate than a direct table? Does compacting the experimentation / failed attempts help or hurt?
Anyway, this is a fun area of research. So definitely drop me a line if this topic interests you! I don’t think this is the holy grail of search, but fun to explore how we can use expensive reasoning processes to create cheaper to run code. Check out my training if agentic search interests you!
Upcoming course: Build your own vector database

Want to understand what makes embedding retrieval fast, relevant, and useful in real AI systems? Join Build your own vector database and build the core pieces yourself, from embeddings and indexing to search and retrieval.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky