One huge gap I see in the RAG community is an over emphasis on human (or LLM) evals and lack of engagement based evals (ie clicks, conversions). Maybe RAG apps are too early in the build phase to have tons of live users?
Or actually, as I suspect it’s just a hard problem? Let’s discuss!
Measurement differences
John Berryman asked me how I might distill my knowledge about search in late 2010s. Well pre ChatGPT, I spent a lot of time on Learning to Rank models. But forget the ML part, what I really did was turn clicks on search results into training data / evals (the actual hard part).
The flow went something like:
- Thousands of users search for “red shoes”
- We aggregate clickstream data over queries - some proportion of sessions click (purchase, whatever) on a great pair of shoes (👠), fewer click on another pair —🩰.
- We account for issues like position bias - users tend to click higher up in the ranking - and presentation bias - users can’t interact with what they don’t see - and many other biases, data sparsity issues, etc. I can’t say we had silver bullets, but at least the problems were well understood (See the topic of Click Models.)
- We come out with a set of labels for which shoes are preferred for red or not, maybe something like:
| Query | Product | Probability of Relevance |
|---|---|---|
| red shoes | 👠 | 0.75 |
| red shoes | 🩰 | 0.25 |
Then we go off and train a model on this large amounts of engagement data. And mostly depending on the quality of the training data, features, etc we’d succeed or fail.
Now think about RAG / chat:
- Users have long conversational questions / chats like “What are the tax returns of X organization from dates YYYY-YYYY).
- These are typically one-offs - you can’t aggregate them very easily. At least using the strings as keys. Thousands of people didn’t ask “What are the tax returns…”
- Users might not even SEE the raw results and interact with them, instead they interact an LLM’s own summary of an answer
- So there’s no big table of “thousands of ‘red shoes’ sessions led to a set of products being interacted with / purchased” etc
As RAG teams learn more about search, they realize they need gather labels. They learn about traditional search evaluation (ie judgment lists, etc). They create their own labels, or gather labels from humans, or they use an LLM as a judge.
But this means, we miss the subtle signals real user interaction in apps tell us. This matters a great deal in many domains - shopping, social media, etc. In these domains, user’s subjective, revealed preferences often matter more than some objective, “wikipedia level” truth we can infer from the data.
For example, in my time at Reddit, human evals would see a search for “cybertruck” and expect cybertruck reviews. In reality, people’s lizard brains just wanted to see cybertruck owners being embarrassed. And that’s just scratching the surface on the PG-13, R and beyond search behavior we had to contend with on what seemed to be otherwise PG searches.
What data would we even gather?
I think we could lump RAG apps into three buckets. Each dictates different data that’s gatherable
A chat alongside traditional results
(ie a shopping experience)
Here were literally chatting about search results. At least we can gather traditional per-session search analytics of products clicked, skipped, etc in a normal result listing. Such as AI Fashion Stylist, Daydream.
A chat with citations / links out to search results
(ie deep research or something like Reddit answers)
Here we have a conversational response, but linked out to specific content that might help.

Engagement on each Reddit post might be possible. But we probably should expand beyond that to look at other analytics signals in the chat itself. Such as hovers over the answer, copy-pasting, and other such analytics.
Focus on useful actions!
Don’t just rely on thumbs up / down, but build in useful actions the user can take on each search result. Such as bookmark, share, expand to see more, etc. Regular users won’t give explicit feedback, but they will take actions that give them, and their lizard brains, value. Youtube does this sneakily by having a video start playing with a hover. Other sites sneakily force you to expand to finish reading an article, and so on.
Completely invisible RAG that doesn’t even tell you it’s searching — it just presents information
I’d just say is don’t do this! Tell the user you’re searching. Be transparent, and give them breadcrumbs on how/where search results are being injected into the context. In other words, switch to the deep-research, citation heavy modality and build in useful ways for users to zero-in on the information from those results.
How can we aggregate queries?
Aggregating many sessions into aggregated data over a single logical query across all users give us deeper insights. Just like the red shoes example above, we could learn that across all “identical” queries, some results are preferred over others by most users.
But this turns into a search problem within search. We need to take queries like:
- What is the best restaurant in Charlottesville VA?
- What are great restaurants in Charlottesville VA?
And treat them the same. But not group these with:
- What are good kid-friendly restaurants in Charlottesville VA?
- Which restaurant has the best menu and ambiance in Charlottesville VA?
Oh boy, this means another labeling effort, and another type of evals for the team to spend months arguing over.
Aggregating probabilistically
According to miniLM, the cosine similarity of “What is the best restaurant…” and “What are great restaurants….” is 0.989. But the cosine similarity of “What is the best restaurant…” and “What are good kid-friendly restaurants…” is a bit lower at 0.951.
We could simply have a cutoff and take a query like “What is the best restaurant…” and group any clicks, etc with those queries > 0.98 similar in LLM. Include “great restaurants” but not “kid friendly restaurants”
But what if we just treated this similarity as a probability that relevant results for one query would also apply to another query?
As in we have these two tables corresponding to search sessions:
| Query | Click? | |
|---|---|---|
| What is the best restaurant in Charlottesville VA? | C&0 Restaurant | 1 |
| What is the best restaurant in Charlottesville VA? | Alley Light | 0 |
| What is the best restaurant in Charlottesville VA? | Fluerie | 1 |
| Query | Click? | |
|---|---|---|
| What are great restaurants in Charlottesville VA? | C&0 Restaurant | 1 |
| What are great restaurants in Charlottesville VA? | Public Fish and Oyster | 1 |
| What are great restaurants in Charlottesville VA? | Alley Light | 1 |
| Query | Click? | |
|---|---|---|
| What are some great kid friendly restaurants in Charlottesville VA? | Chew Chew Town | 0 |
| What are some great kid friendly restaurants in Charlottesville VA? | Three Notched | 1 |
| What are some great kid friendly restaurants in Charlottesville VA? | Public Fish and Oyster | 0 |
We put all our queries into a vector index, and notice when we want to understand the ground truth for “What is the best restaurant in Charlottesville VA?” we get a set of queries back, along with associated cosine similarity, with probability scaled from -1 to 1 to 0 to 1.
What is the best restaurant in Charlottesville VA? (Similarity 1.0)
What are great restaurants in Charlottesville VA? (Similarity 0.989, p=0.9945)
What are some great kid friendly restaurants in Charlottesville VA? (0.95, p=0.975)
…
Then we build a larger table, aggregating the clicks probabilistically:
As in we have these two tables corresponding to search sessions to get a click-thru-rate:
| Query | Mean(CTR query A * p query A + CTR query B * p query B …) | |
|---|---|---|
| What is the best restaurant in Charlottesville VA? | C&0 Restaurant | Mean(1.0 * 1.0 + 0.9945 * 1) = 0.99725 |
| What is the best restaurant in Charlottesville VA? | Alley Light | Mean(0* 1.0 + 1 * 0.9945) = 0.49725 |
| What is the best restaurant in Charlottesville VA? | Public Fish and Oyster | Mean(10.9945 + 10.975) = 0.98475 |
Using the beta distribution to model uncertainty in similar queries
Notice above just on very little data we jump to immediately certain some of these results are (ir)relevant. That’s less than ideal, as we have a tremendous amount of uncertainty.
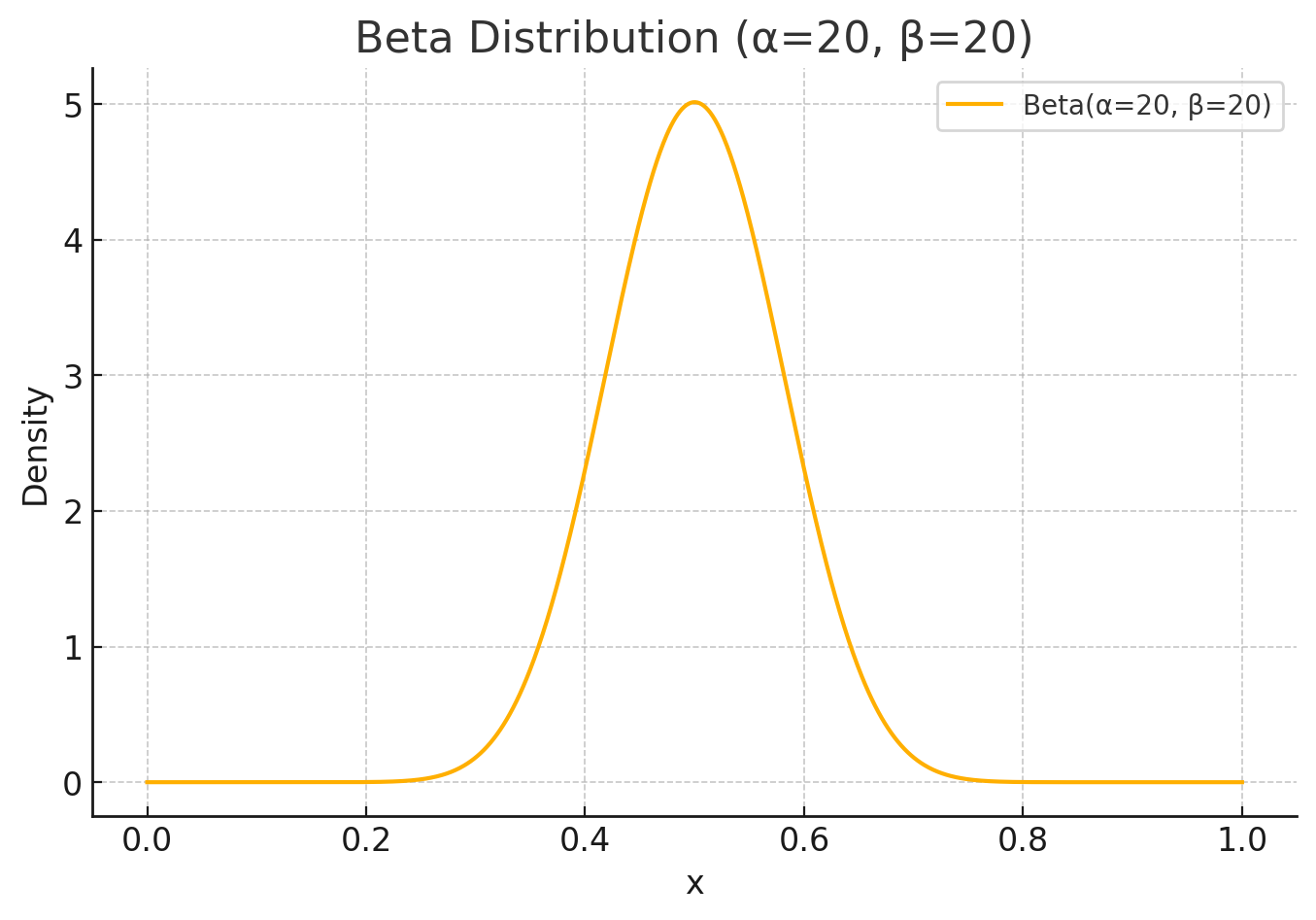
To module uncertainty, we could use the beta distribution. Beta distribution helps us understand our confidence in the data. For example, one coin flip we know very little about the weighing of the coin. But after many, that certainty tightens up around the true bias of the coin (perhaps slightly heads or something).
With the distribution we start with an alpha and beta. Let’s start with 20 for alpha and 20 for beta. The expected value is alpha / (alpha + beta)
In our case 20 / (20 + 20) = 0.5
Or as a distribution:
When we encounter a success case (heads on a coin, a search result is clicked) we would increment alpha. A failure case (search result shown, but not clicked) you would increment beta.
So user searches for “What is the best restaurant in Charlottesville VA?” and they click “C&O restaurant” we add a 1 to alpha:
21 / (21 + 20) = 0.51
Graphed:
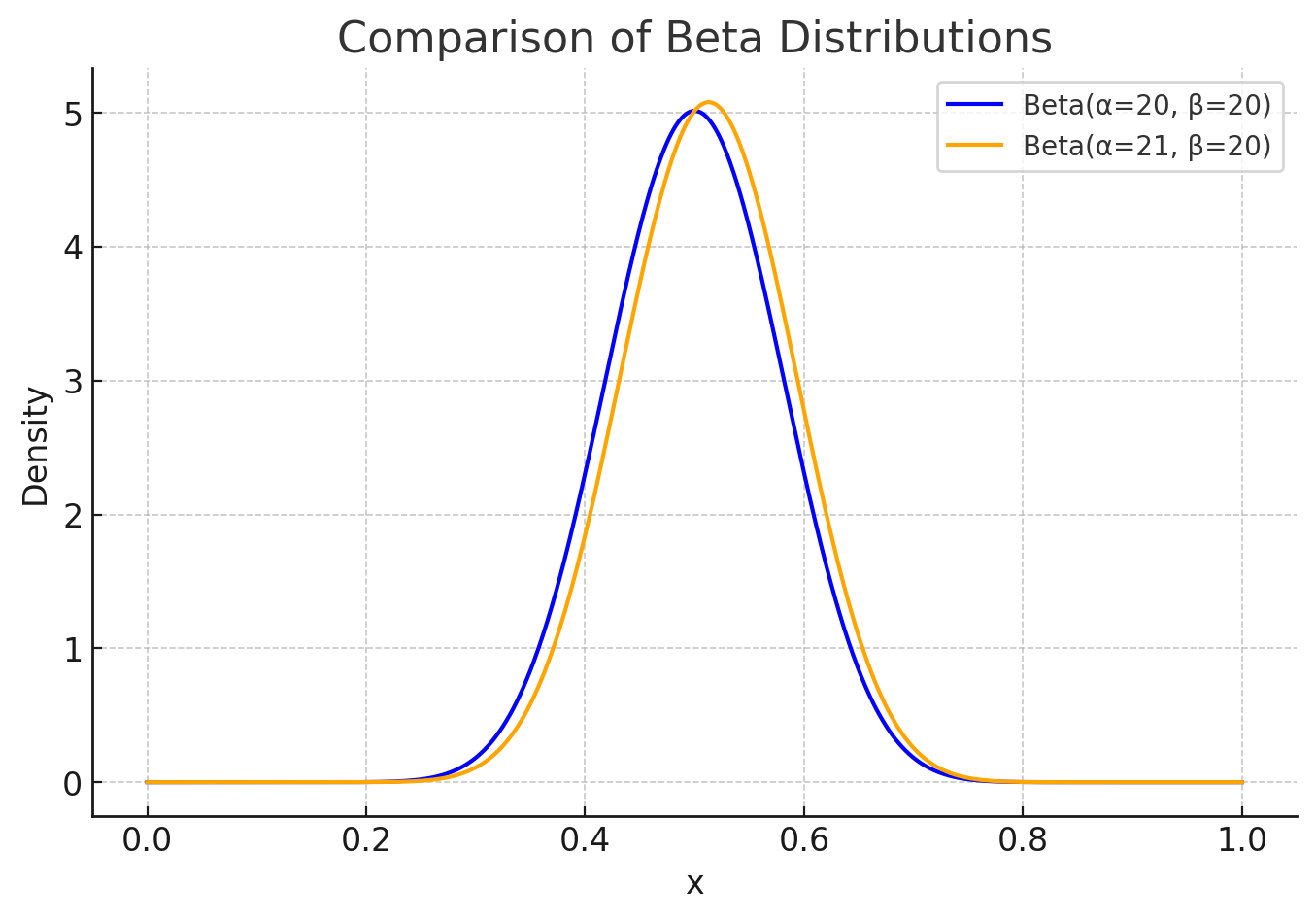
We nudged up the expected value closer to truthyness that, indeed, this is a great restaurant.
We model BOTH uncertainty and probability. This matters a lot for sparse queries like long-tail queries or chats. As more traffic gravitates to “C&O” both alpha and beta increment, and we get closer to a “true” probability with less uncertainty. Eventually if we get a lot of traffic, our uncertainty shrinks, and the distribution narrows. Lets look at alpha=100, beta=40
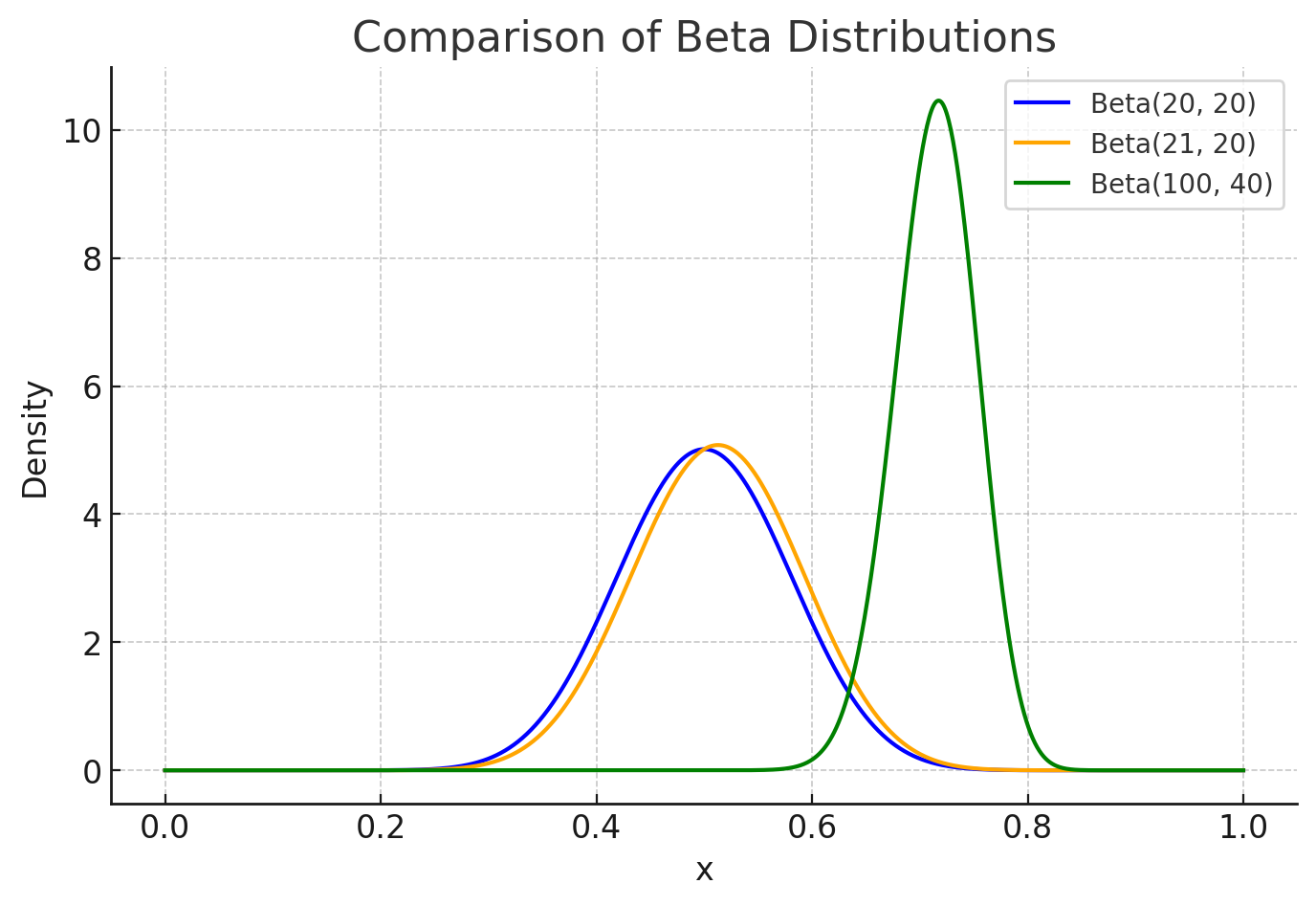
But back to nearest neighbors, we could also increment alpha / beta using the similarity to our main query.
For Alley Light, we have 0 clicks on a session with similarity = 1. And 1 click on a session with similarity = 0.989. We could increment alpha by 0.989 and beta by 1, giving:
20.989 / (20.989 + 21) = 0.4998
Over many similar queries, we can gradually begin to model confidence of what might actually be relevant for this query.
Improvements / unanswered questions
Better similarity between queries?
I’m using a rather naive way to consider two queries similar - their cosine similarity on an embedding model. What better ways could exist to consider queries similar? Are there models that consider the probability two queries would have similarly relevant results. After all, that’s a better way to measure what we want.
Instead of using an embedding model, should we turn the query into a structured entity? IE turn “red shoes” and “I want red shoes” into color:red, itemType:shoe . Then aggregate over this string?
Indeed this dovetails with query understanding, and presumes our ability to decompose queries works well. It also requires that we know apriori the actual structure of our queries now and forever. Still, we can iterate and change over time.
Combining multiple turns into a single turn
I have a hypothesis, that generally, for search eval, we can probably turn a long conversation into a summarized question. That might be a crucial preprocessing step for any of this to work.
What about the other biases?
Do we know what biases exist in interaction of RAG search results? Like search, will users prefer to interact with top results? And similar to search - how do we account for presentation bias (users not clicking what they never see)?
Use to improve the RAG result relevance?
We could use this approach to improve RAG results themselves. In search we have a concept known as “signals”. This is basically just looking up past, relevant results of a query and boosting those results at query time.
We could do this, but use a vector index for queries. Searching our query index for What is the best restaurant in Charlottesville VA? and boosting the results of What are great restaurants in Charlottesville VA? based on the similarity of the query.
Get in touch!
Are my ideas insane? Please get in touch if I can in any way help you think through RAG, AI, or search problems. I’d love to be your fractional search team lead :). And check out my upcoming Cheat at Search with LLMs training course.
Upcoming events: Vectors Week

Join me for Vectors Week, a series of events about vector retrieval, hybrid search, and building your own vector database.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky