I want you to share in my shame at daring to make a search library. And in this shame, you too, can experience the humility and understanding of what a real, honest-to-goodness, not side-project, search engine does to make lexical search fast.
BEIR is a set of Information Retrieval benchmarks, oriented around question-answer use cases.
My side project, SearchArray adds full text search to Pandas. So naturally, to see stand in awe at my amazing developer skills, I wanted to use BEIR to compare SearchArray to Elasticsearch (w/ same query + tokenization). So I spent a Saturday integrating SearchArray into BEIR, and measuring its relevence and performance on MSMarco Passage Retrieval corpus (8M docs).
… and 🥁
| Library | Elasticsearch | SearchArray |
|---|---|---|
| NDCG@10 | 0.2275 | 0.225 |
| Search Throughput | 90 QPS | ~18 QPS |
| Indexing Throughput | 10K Docs Per Sec | ~3.5K Docs Per Sec |
… Sad trombone 🎺
It’s worse in every dimension
At least NDCG@10 is nearly right, so our BM25 calculation is correct (probably due to negligible differences in tokenization)
Imposter Syndrome anyone?
Instead of wallowing in my shame, I DO know exactly what’s going on… And it’s fairly educational. Let’s chat about why a real, non side-project, search engine is fast.
A Magic WAND
(Or how SearchArray is top 8m retrieval while Elasticsearch == top K retrieval)
In lexical search systems, you search for multiple terms. You take the BM25 score of each term, and then finally, combine those into a final score for the document. IE, a search for luke skywalker really means: BM25(luke) ??? BM25(skywalker) where ??? is some mathematical operator.
In a simple “OR” query, you just take the SUM of each term for each doc, IE, a search for luke skywalker is BM25(luke) + BM25(skywalker) like so:
| Term | Doc A (BM25) | Doc B (BM25) |
|---|---|---|
| luke | 1.90 | 1.45 |
| skywalker | 11.51 | 4.3 |
| Combined doc score (SUM) | 13.41 | 5.75 |
SearchArray just does BM25 scoring. You get back big numpy arrays of every document’s BM25 score. Then you combine the scores – literally using np.sum. Of course, that’s not what a search engine like Elasticsearch would do. Instead it has a different guarantee, it gets the highest scoring top N of your specified OR query.
This little bit of seemingly minute wiggle room gives search engines a great deal of latitude. Search engines can use an algorithm called Weak-AND or WAND to avoid work when combining multiple term scores into the final top N results.
I won’t get into the full nitty gritty of the algorithm, but here’s a key intuition to noodle over:
A scoring system like BM25 depends heavily on document frequency of a term. So rare terms - a high (1 / document frequency) - have a higher likelihood of impacting the final score, and ending up in the top K. Luckily these terms (like skywalker) occur on fewer documents. So we can fetch these select, elite few docs quickly in the data structure that maps skywalker -> [... handful of matching doc ids...] (aka postings). We can reach deeply into this list.
On the other hand, we can be much more circumspect about the boring, common term, luke. And that’s useful because luke has a very extensive postings list luke -> [... a giant honking list of documents...]. We’d prefer to avoid scanning all of these.
We might imagine that these lists of document ids, also is paired with its term frequency how often that term occurs in that document - the other major input of BM25. And if its SORTED from highest -> lowest term frequency, we can go down this list until its impossible for the BM25 score of a term to have any chance of making the top K results. Then exit early.
While WAND - and similar optimizations - helps Elasticsearch avoid work, SearchArray, gleefully does this work like an ignoramus happily giving you a giant idiotic array of BM25 scores.
When you look at this icicle graph of SearchArray’s performance doing an “OR” search, you can see all the time spent summing a giant array and also needlessly BM25 scoring many many documents.
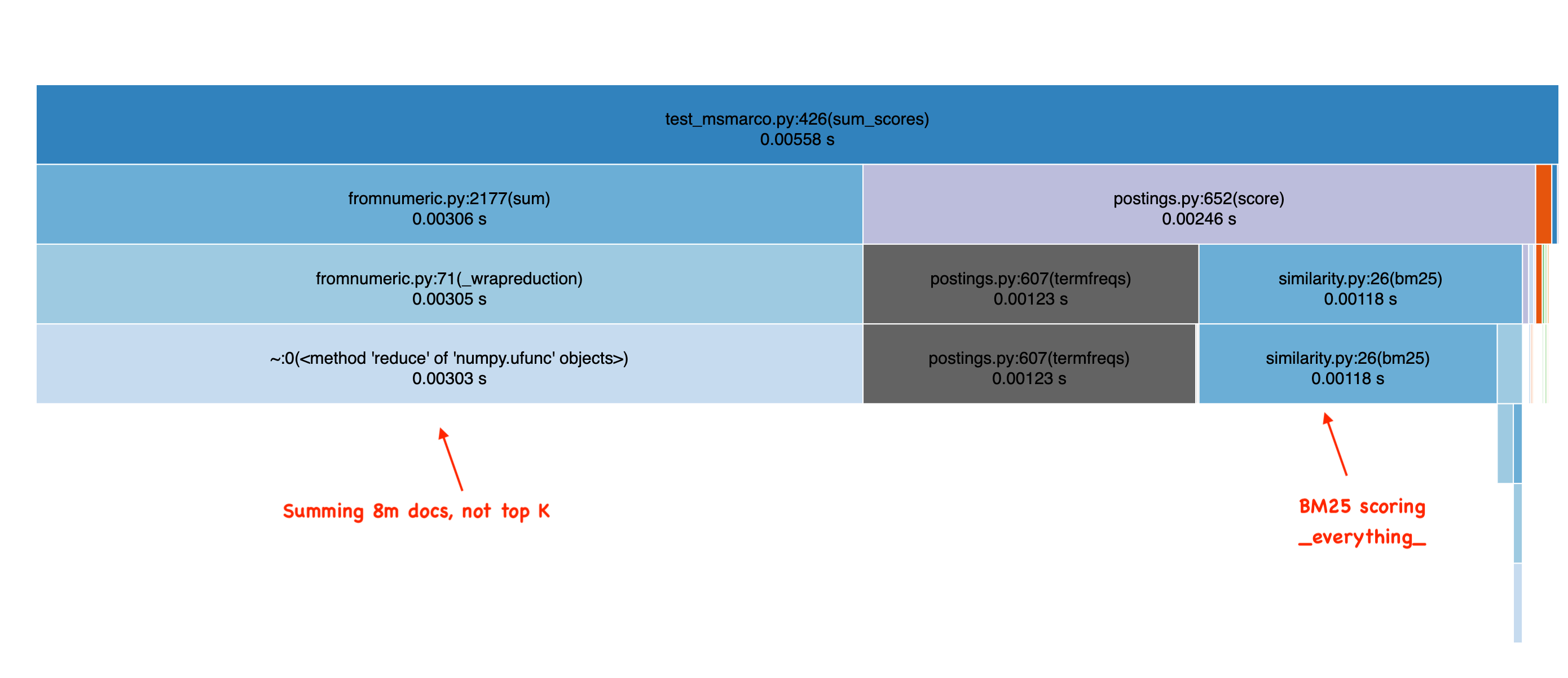
SearchArray doesn’t directly store postings
Unlike most search engines, SearchArray doesn’t have postings lists of terms -> documents.
Instead, under the hood, SearchArray stores a positional index, built first-and-foremost for phrase matching. You give SearchArray a list of terms ['mary', 'had', 'a', 'little', 'lamb']. It then finds every place mary occurs one position before had, etc. It does this by storing, for each terms, the positions as a roaring bitmap.
In our roaring bitmap, each 64 bit word has a header indicating where the positions occur (document and region in the doc). Each bit position corresponds to a position in the document. A 1 indicates this term is present, a 0 missing.
So to collect phrase matches, for mary had we can simply find places where one term’s bits occur adjacent to another. This can be done very fast with simple bit arithmetic.
mary
<Roaring Headers (doc id, etc)> 00000010000000 | 00000000000010
had
<Roaring Headers (doc id, etc)> 00000001000000 | 00000000000001 #< Left shift 1, AND, count bits to get phrase freq
...
But a nice property of this, and alleviating maintenance for this one person project, is the fact that we can also use this to compute term frequencies. Simply by performing a popcount (counting the number of set bits), then collecting those documents for a term, we get a mapping of doc ids -> term frequencies.
So we spend a fair amount of time doing that, as you can see here:
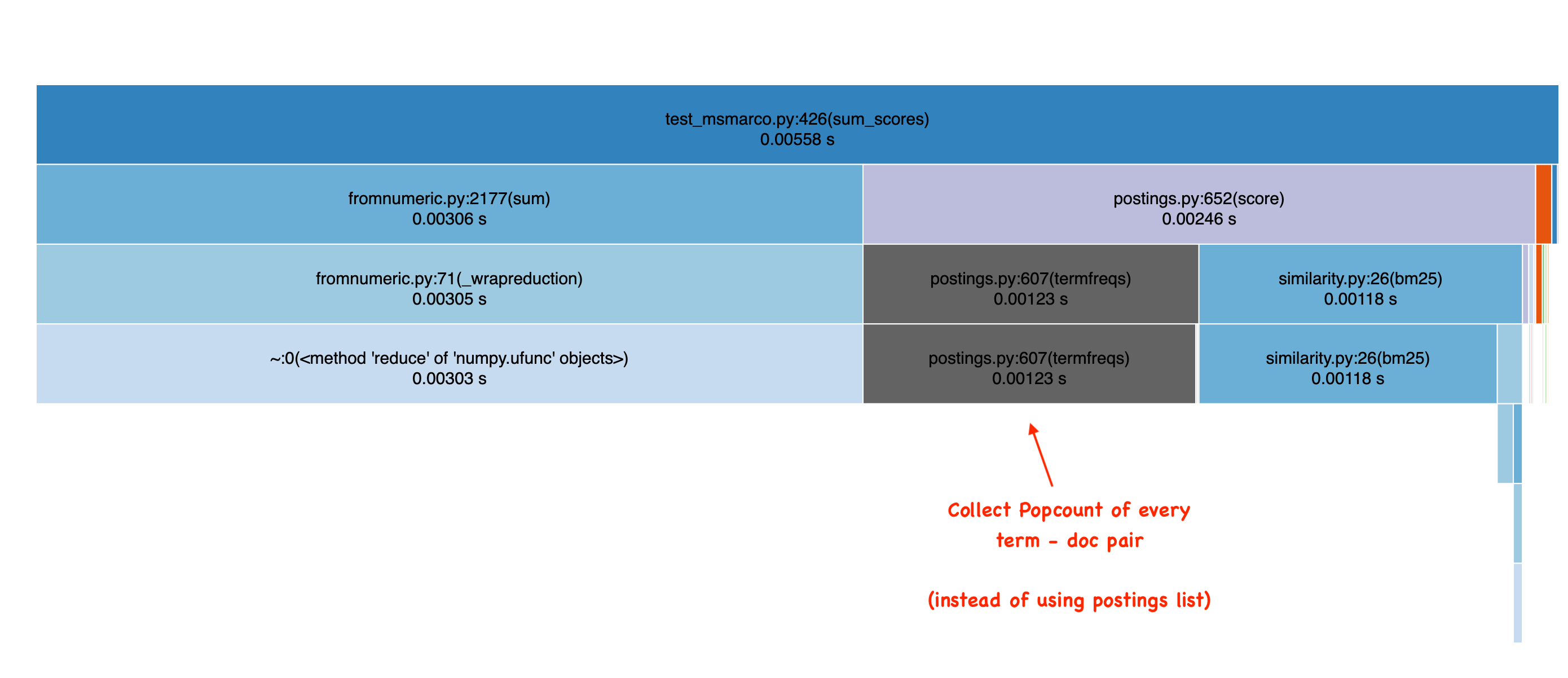
Now I lied actually, while this is the core mechanism for storing term frequencies, we do cache. A cache that remembers the doc id -> term frequencies when the roaring bit array is > N 64 bit words. This lets users tune N to your memory / speed tradeoff, and get closer to a postings list.
Caching Non term-dependent BM25 components
Take a look at this snippet for computing BM25:
bm25 = (
term_freq / (term_freq + (k1 * ((1 - b) + (b * (doc_len / avg_doc_lens)))))
) * idf
Notice there is a BIG PART of this calculation that has nothing to do with the terms being searched:
(k1 * ((1 - b) + (b * (doc_len / avg_doc_lens)))))
In my testing, a bit of latency (1ms on 1 million docs) can be shaved by caching everything in the k1 + ... avg_doc_lens somewhere. If doc_len corresponds to array with a doc length value for every document, you can create an array with this formula cached. But it’s a bit of a maintenance burden to have one additional, globally shared cache. So I have avoided this so far.
Caching the FULL query, not just individual BM25 term scoring
SearchArray is just a system for computing BM25 scores (or whatever similarity). You USE it to build up an “or query” or whatever using numpy… it doesn’t do it for you. IE the code implemented in BEIR is simply:
def bm25_search(corpus, query, column):
tokenizer = corpus[column].array.tokenizer
query_terms = tokenizer(query)
scores = np.zeros(len(corpus))
query_terms = set(query_terms)
for term in query_terms:
scores += corpus[column].array.score(term)
return scores
But in a regular search engine like Solr, Elasticsearch, OpenSearch, or Vespa, this logic is expressed in the search engine’s Query DSL. So the search engine can plan+cache the complete calculation, whereas SearchArray gives you all the tools to shoot yourself in the foot, performance wise (not to mention the earlier point about WAND, etc).
That’s why you should hug a search engineer
There you have it!
SearchArray is a tool for prototyping, using normal Pydata tooling, not for building giant retrieval systems like Elasticsearch. It’s good to know the tradeoffs behind your lexical system, as they focus on different tradeoffs. You might find it useful for dorking around on < 10 million doc datasets.
What would be great would be if we COULD express our queries in such a dataframe-oriented DSL. IE a Polars-esque lazy top-N retrieval system that pulled from different retrieval sources, scored them, summed them, and did whatever arbitrary math to the underlying scores. I can cross my fingers such a thing might exist. So far people build these DAGs in less expressive ways: as part of their Torch model DAG, or some homegrown query-time DAG system.
In any case, I’m absolutely humbled by folks that work on big, large scale, distributed lexical search engines like (Vespa, Lucene, OpenSearch, Elasticsearch, Solr). These folks ought to be your hero too, they do this grunt work for us, and we should NOT take it for granted.
Below are some notes and appendices for BEIR and the different benchmarking scripts, in case you’re curious
Appendix links to scripts
Appendix - How to integrate with BEIR…
BEIR has a set of built-in datasets and metrics tools, if you implement a BaseSearch class with the following signature:
class SearchArraySearch(BaseSearch):
def search(self,
corpus: Dict[str, Dict[str, str]],
queries: Dict[str, str],
top_k: int,
*args,
**kwargs) -> Dict[str, Dict[str, float]]:
The inputs:
- Corpus: A dict pointing a document id to a set of fields to index, ie
{'text': 'The presence of communication amid scientific minds was equally important to the success of the Manhattan Project as scientific intellect was. The only cloud hanging over the impressive achievement of the atomic researchers and engineers is what their success truly meant; hundreds of thousands of innocent lives obliterated.',
'title': ''}
...
- Queries: A dict pointing a query id -> query:
{"1": "Who was the original governor of the plymouth colony"}
...
Finally the output is a dictionary of query ids -> {doc ids -> scores} - each query w/ top_k scored.
So when search is called you need to
- Index the corpus
- Issue all queries and gather scores
Essentially this looks something like:
def search(self,
corpus: Dict[str, Dict[str, str]],
queries: Dict[str, str],
top_k: int,
*args,
**kwargs) -> Dict[str, Dict[str, float]]:
corpus = self.index_corpus(corpus) # <- add tokenized columns to dataframe
results = {}
for query_id, query in queries.items(): #<- search and gather results
results_for_query = some_search_function(corpus, query)
results[query_id] = get_top_k(results_for_query)
return results
How does this look for SearchArray?
To index, we loop over each str column, and add a SearchArray column to the DF. Below, tokenized with a snowball tokenizer:
for column in corpus.columns:
if corpus[column].dtype == 'object':
corpus[column].fillna("", inplace=True)
corpus[f'{column}_snowball'] = SearchArray.index(corpus[column],
data_dir=DATA_DIR,
tokenizer=snowball_tokenizer)
Then replace some_search_function above w/ something that searches the SearchArray columns. Maybe this simple bm25_search:
def bm25_search(corpus, query):
query = snowball_tokenizer(query)
scores = np.zeros(len(corpus))
for q in query:
scores += corpus['text_snowball'].array.score(q)
return scores
(Leaving out some annoying threading, but you can look at the code all here )
Upcoming course: Build your own vector database

Want to understand what makes embedding retrieval fast, relevant, and useful in real AI systems? Join Build your own vector database and build the core pieces yourself, from embeddings and indexing to search and retrieval.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky