Agentic search gets interesting when agents do not know how to find the right answer.
Oh, the agent might think it knows. It might confidently BS us. But the agent’s poor domain intuition steers itself astray.
Agents make false assumptions about what our users think is relevant. Our fashionista users think “red shoes” should return high-heels. When I worked at one company ABE wasn’t a president, it was an A/B testing tool. Agents need context to know these things - and context engineering needs agentic search
Confusingly, depending who you talk to, agentic search can mean one of three distinct implementation patterns:
- Retrieval-centric - just build good search so agents can use it to fill in missing context
- Harness-centric - steer the agent towards needed context, even with bad search
- Model-centric - fine-tune an LLM to know how to search our data
In this post, I’ll walk through each. With a bit more context, you might appreciate which flavor your colleagues seem to mean when they say “agentic search”
Retrieval-Centric Implementation
When frontier models don’t know, they search. Ask ChatGPT a question about news, it’ll search. Ask it about a very specific technical problem, it’ll search. During training, LLMs see search examples as a technique to learn what they don’t know.
Therefore, we just need to build good search to solve any conceivable query from an agent.
Let’s assume we run an e-commerce catalog. For us, when users search “red shoes” they mean “red high heels”. But the agent doesn’t know that. Luckily it asks search. Below we see it returns the right results.
Below we see initial retrieval to lexical / vector backends pulls back some reasonable, if naive, “red shoe” candidates. Still that’s not quite right. Luckily the reranker shapes the results towards our understanding of that intent.
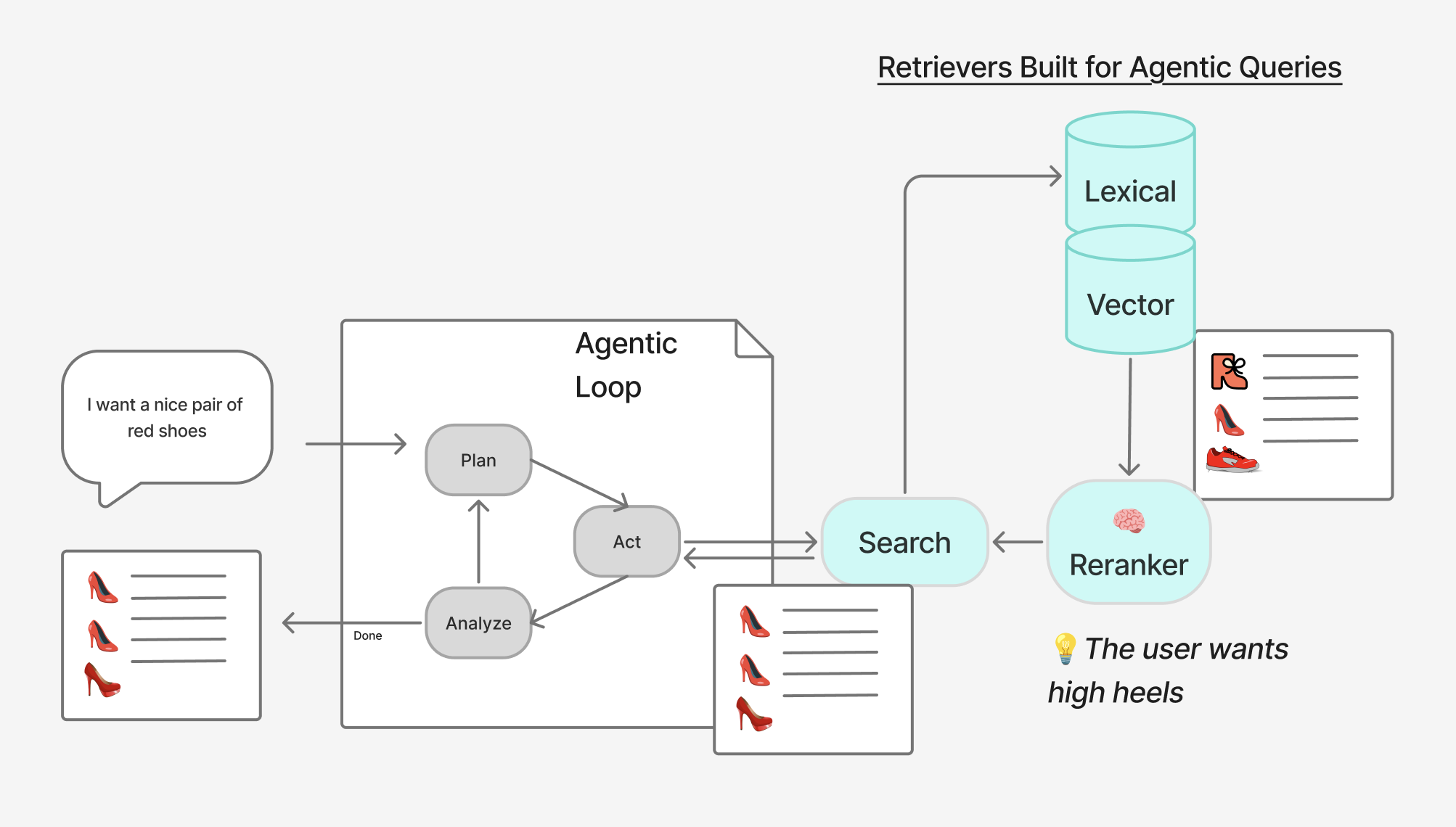
Of course we might have other components here - query understanding, diversity, custom embedding models, and more.
The important point is that search leads the agent by the nose towards what’s relevant. We assume search can define what a good “red shoe” is, overriding the agent’s perspective.
When RAG answers don’t look like answers
Most teams build retrieval-centric approaches with classic RAG. Chunks of answers and embeddings trained to recognize them as answers.
Unfortunately, answers don’t always look tied to the question. For example:
Question:
Synopsis of the book Ubik
Answer:
By the year 1992, humanity has colonized the Moon and psychic powers are common. The protagonist, Joe Chip, is a debt-ridden technician working for Runciter Associates, a “prudence organization” employing “inertials”—people with the ability to negate the powers of telepaths and “precogs”—to enforce the privacy of clients.
If you don’t know the book Ubik, it’s not clear that this answers the question. The agent says “cool story bro” and ignores the info.
Search like this actually is divorced from the web search trusted by frontier models. The web contains titles, headings, and other elements placing the answer in context.
The big downside? Search remains hard. We’re not Google.
Most importantly, we don’t have perfect search like Google or Bing. Even with good search - almost nobody builds Google-quality results. And since agents trust search - simple distractors in retrieval can, as Lester Solbakken says, easily confuse reasoning.
Harness-centric implementations
Who should be in charge? Should the agent manage the search process? Or should search drive the agent?
Moving the emphasis to the harness, we put the agent in charge.
Imagine stripping search tools down to core retrieval primitives. Just a BM25 backend. Or a filesystem with CLI tools. We tell the agent to find what it needs with these untuned tools. The agent might struggle more, but hey, it’s smart, it can figure it out. Right?
Still, the agent might find what it thinks is relevant, as it does in the image below. Sadly that’s not what’s actually relevant. To help the agent, we inject external knowledge. We let a judge direct the agent, correcting its mistakes, and guiding it towards better search strategies.
So when the agent returns results, it’s not the “user” that receives the candidates. Instead a judge labels results as relevant or not. The agent gets the hint, finding results similar to those labeled relevant. Avoiding those labeled irrelevant. To steal from Jo Kristian Bergem, this is relevance feedback on steroids.
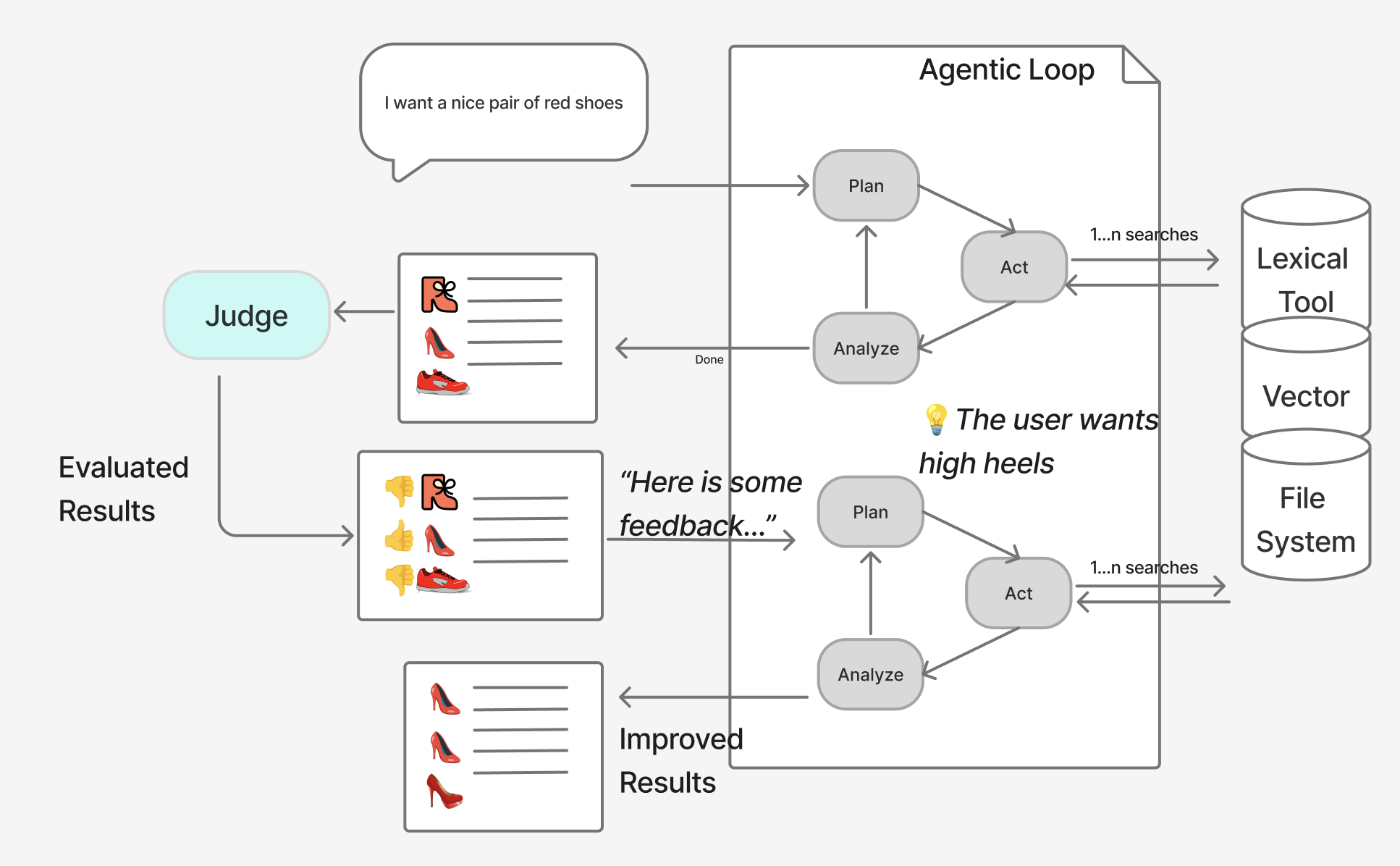
This works. Look at the ESCI dataset. If I have an oracle labeling with judgments from these datasets, I get quite significant improvements.
| Variant | NDCG@10 | Description |
|---|---|---|
| ESCI BM25 | 0.2895 | Simple BM25 weighing name / description |
| ESCI agentic | 0.4101 | GPT5-mini tool calling loop w/ BM25+e5 embeddings tools |
| ESCI agentic w/ oracle | 0.5843 | GPT5-mini tool calling loop w/ BM25+e5 embeddings tools. Judge responds with feedback once |
Here the second row we trust the agent’s interpretation of queries. That provides a large gain over BM25. But inject more domain knowledge via a judge (the third row) and agent performance improves dramatically.
We can guide agents with information ahead of time too. For example, I’ve seen teams take inspiration from skills in coding agents. Imagine a targeted query plan that tells the agent how to use its tools to solve a specific problem.
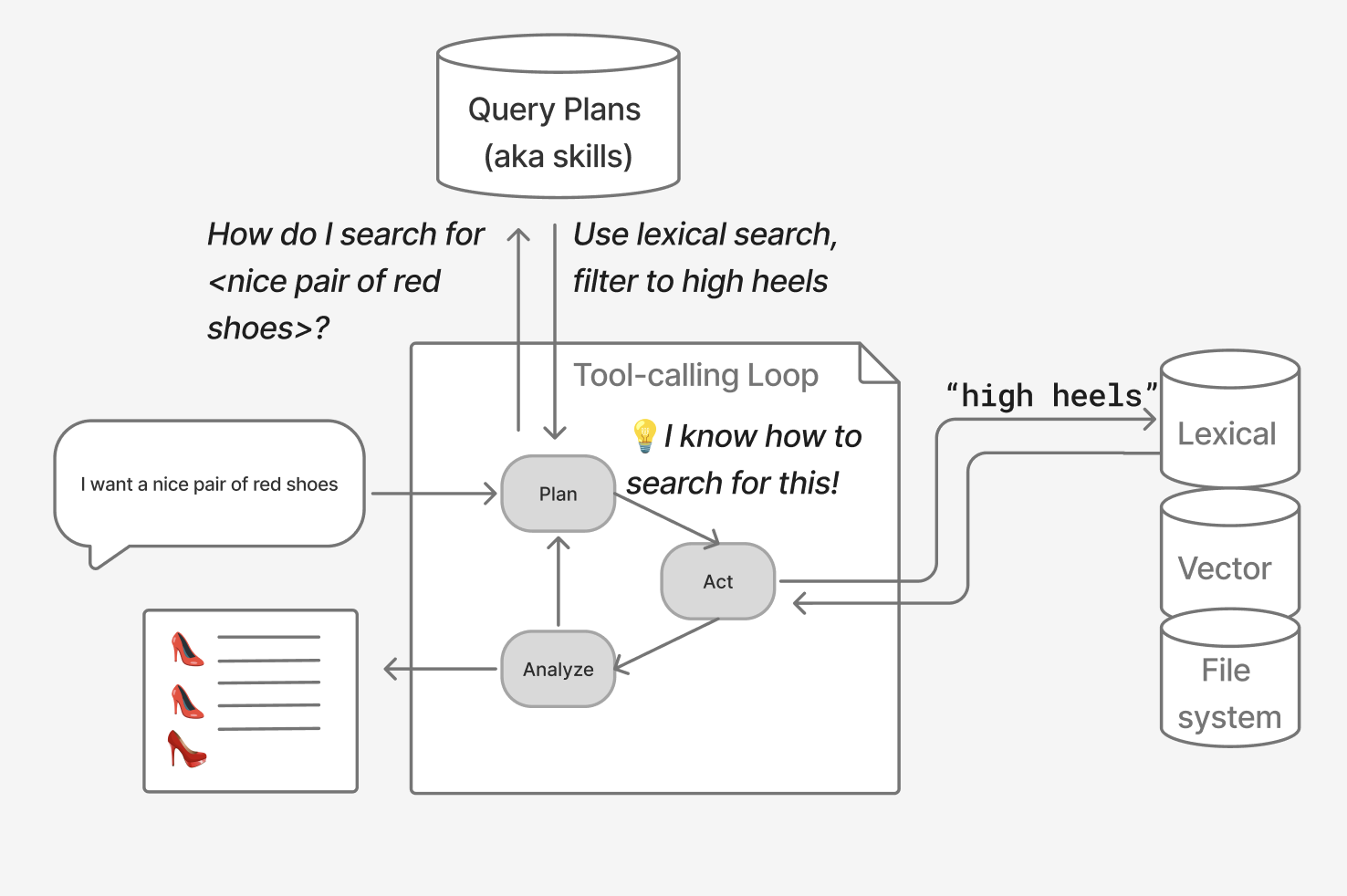
Optimizing content helps harnesses
We help agents even further by optimizing content for findability. That’s the trick we’ve played on ourselves with coding agents. We write docs to explain to agents why something’s useful. We don’t just rely on that dumb chunk, we document the purpose of the knowledge:
/books/scifi/ubik.txt
## About Book Ubik Ubik is a book by Philip K. Dick
## Synopsis
By the year 1992, humanity has colonized the Moon and psychic powers are common. The protagonist, Joe Chip, is a debt-ridden technician working for Runciter Associates, a “prudence organization” employing “inertials”—people with the ability to negate the powers of telepaths and “precogs”—to enforce the privacy of clients.
Unlike a naive chunk, this bit of information has purpose. It’s clear, when its in the context, what problem it solves.
By organizing + cataloging information we’ve done what every search developer wishes their content team would do: actually optimize content to be findable.
The downside: cost
The major downside here? Token costs. The exploration here requires more than just issuing a search and retrieving one set of results. It’s an agent’s exploration of the environment. And that exploration starts fresh with every new context window.
Model-centric approach
What if we literally fine-tuned the LLM to search efficiently?
The harness based approach takes a long, winding path towards relevant results. With every fresh context, it wastes calls relearning what works over-and-over. It’s costly and slow.
Could we train a model that doesn’t repeat the same mistakes with our tools?
Our judge helps label some of the agent’s reasoning / tool-calling paths as useful. And label others less so. Once you have labeled traces, you can fine-tune an open weights model to proactively, efficiently make the right tool calls given the input.
Below, for example, the model knows exactly how to search for our “red shoes” query given its extensive fine-tuning.
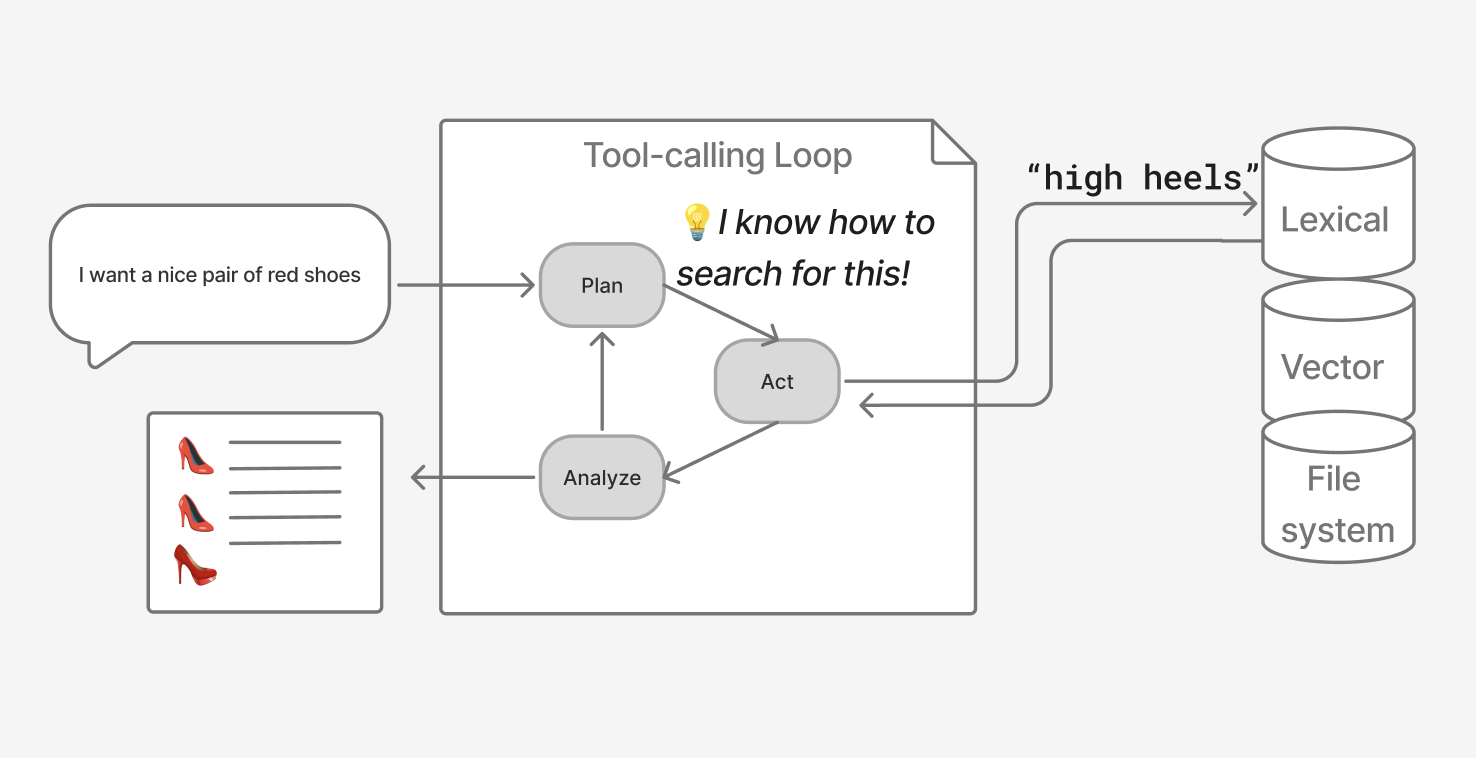
Now we’ve built a model targeting the search task. We don’t tune our retrievers much. Instead we continue to use the simpler / dumb search tools.
Even cooler, the agentic search model’s behavior can change just by adjusting the system prompt. “This is an e-commerce search task, optimize for top 10 ranking” might be different from “You’re retrieving chunks for financial research, maximize diversity and relevance at the same time.”
Further the models can stay smaller. By just focusing on the search part - not the entire domain problem - they can shrink to a manageable size allowing them to be self-hosted.
The downside? Early days
The OG in the space is SID. Other contenders like Glean’s Waldo model have since entered. They’re all promising, but not widely adopted. Many unknown unknowns exist. In a sense, we don’t yet know the upside or downsides yet. I suspect though this paradigm has tremendous promise in the years ahead.
In other words - stay tuned!
The alchemy of ambiguity
People use “agentic search” confusingly and inconsistently. They focus on their part of the problem. That means we have a collection of solutions like enriched base metals - and it’s unclear what alchemy brings them together.
We’re converging on a fascinating mix of easier to organize data (like PageIndex). I’m seeing patterns in harness design that mirror coding agents - hooks / evaluators that steer agents. Or “skills” that guide them a priori. Much like with coding - the agents eat the harnesses. When a successful pattern emerges, agents, in our case agentic search models, train to memorize these patterns.
Retrieval also seems to be moving towards agent-centric approaches. Agents have their own specific, unique retrieval patterns. We’re finally seeing late interaction + learned sparse retrieval approaches have their day from companies like LightOn and MixedBread
We’re swimming in an interesting retrieval primordial goop, what comes out may be an obvious combination - or look nothing like the component parts. Exciting times!
Enjoy softwaredoug in training course form!
Starting May 18!
Signup here - http://maven.com/softwaredoug/cheat-at-search I hope you join me at Cheat at Search with Agents to learn use agents in search. build better RAG and use LLMs in query understanding.
I hope you join me at Cheat at Search with Agents to learn use agents in search. build better RAG and use LLMs in query understanding.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky