In retrieval, we know the Lego pieces well. Embeddings. Rerankers. Query understanding. BM25. All the parts we put together in the standard stack.
But a new power is rising: agentic search models. LLMs trained specifically on controlling the search task. Compared to GPT-5 and pals, these models might focus on tasks / domains. They can be smaller, faster, and easier to deploy in our search infrastructure.
Let’s set the stage.
With the traditional Lego pieces, we build something like this thick search monolith:
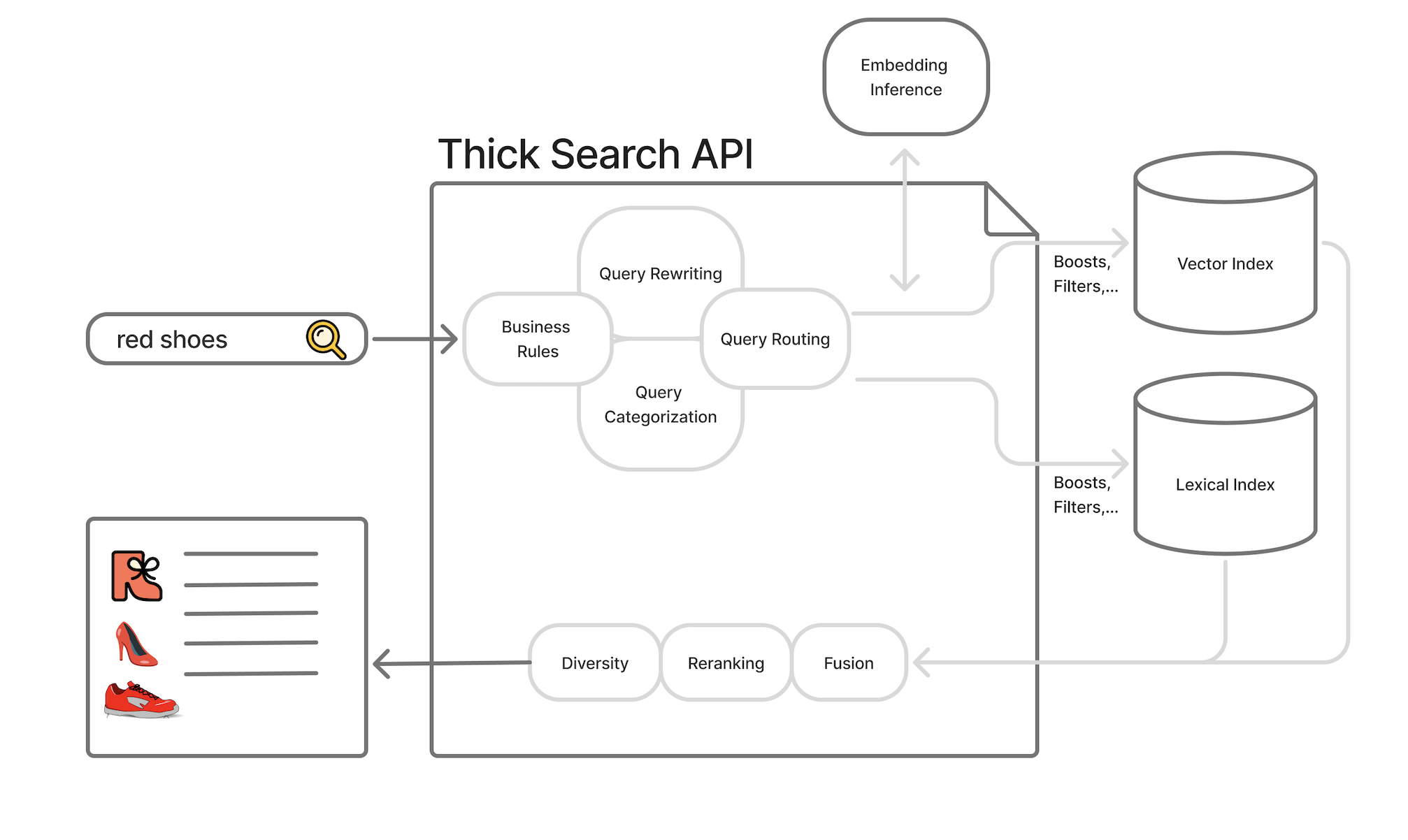
That’s what we’ve built for 1–2 decades. Queries flow into the system. We apply business rules and classify queries. We search one or more retrieval backends. We post-process and rerank what comes back.
It’s all very manual, programmatic, and bespoke. Each piece doesn’t see the whole. Every piece focuses on its part of the problem (rerankers, query classifiers, etc.) ignorant of the whole.
Agentic search orchestrates the pieces
Agentic search unbundles the pieces to see the whole. An agent built on GPT-5 or Sonnet knows it has tools. It’s given knowledge / context to solve the user’s query.
The agent helps the user: driving a few simple retrieval primitives, exploring candidates to return what’s relevant. Instead of thick, monolithic search, the underlying search tools become thin wrappers on our backend indices.
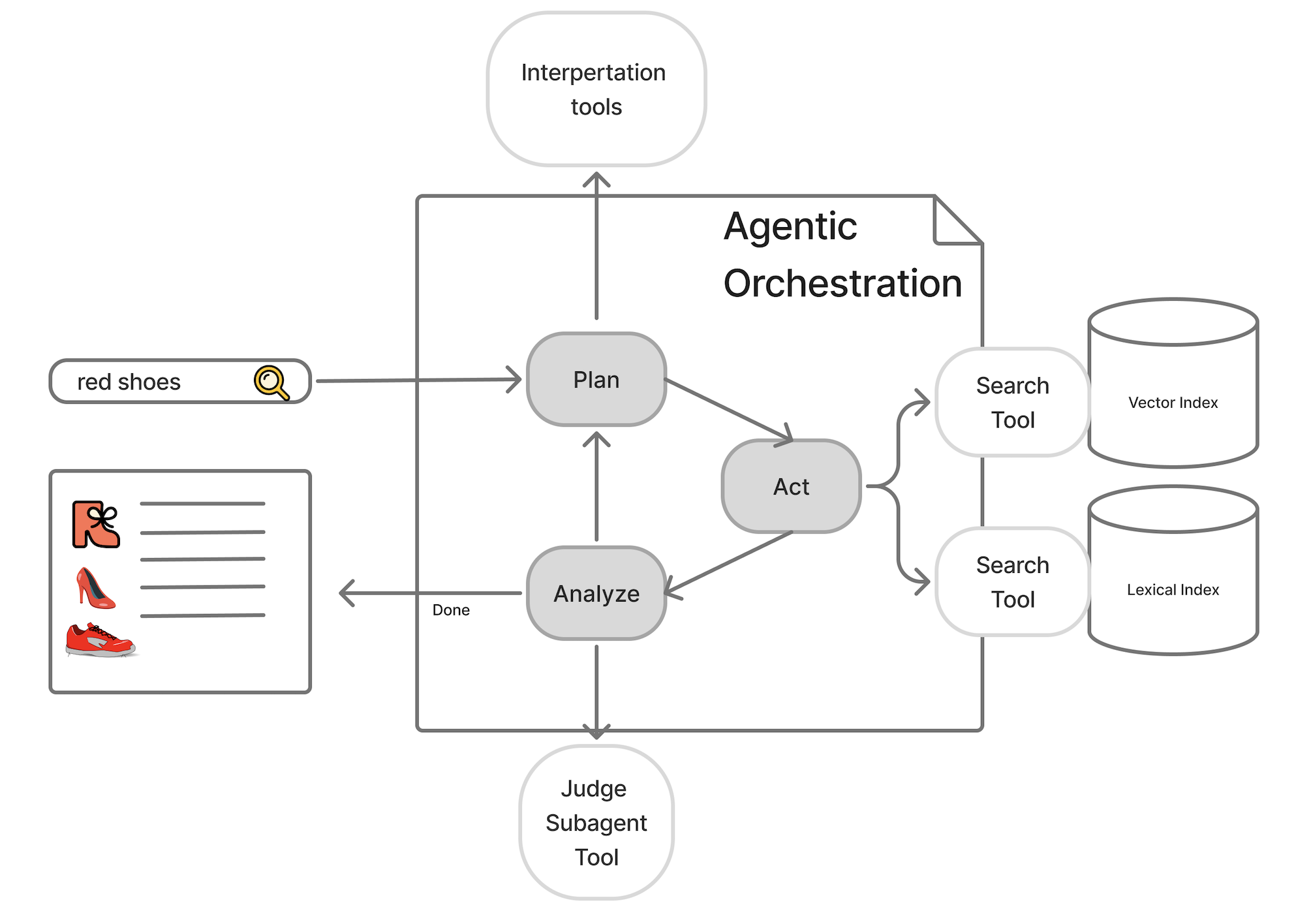
Unlike the traditional stack, the agent sees the whole process. It’s not a series of reductive steps. Instead, the model orchestrates a solution for the user using what’s available - retrieval tools, other subagents, or a knowledge base to guide the user.
In other words, agentic search unbundles the retrieval stack. The parts still matter. But the whole can be managed by a single, intelligent model.
GPT-5 doesn’t really know search
Frontier lab models (GPT-5, Sonnet and pals) do well in the 80% case. They understand the queries with general knowledge. They surface defensible search results.
But it’s the last 20% that moves the needle.
What’s in the last 20%? It’s the non-obvious stuff in our users / domain. GPT-5 doesn’t know that in our furniture store a search for “bistro tables” actually means “small outdoor tables” not restaurant equipment. GPT-5 doesn’t know our fashion search users click on dark or plain patterns over complex ones.
Why not? Isn’t GPT-5 itself also trained on search?
Yes, of course.
GPT-5 and pals think of ‘search’ as web search. Mainline models expect search tools that work near flawlessly. To give them answers they don’t have. Unfortunately, our search isn’t Google. We work on smaller, focused teams: building simpler search backends for our narrow domains. We need agents trained to reason and orchestrate simpler retrieval systems.
Currently, as I teach in Cheat at Search with Agents, we build constraints + checks around the model. But this intense level of context engineering eats up tokens and costs $$.
Agentic search models for the last 20%
What if we could train an LLM to focus on search specifically? Even better: search in our domain, for our users?
We’re beginning to see models in this direction: SID was first with their SID-1 model. We’ve since seen Glean release Waldo. Startups like Charcoal tailor to your corpus.
Teams advertise these replacements by training on document search specifically - they focus on that last 20% needed to find useful results. Sid, for example, points to smaller size and lower latency compared to GPT-5 for agentic search.
Think about the implications. I’ve described a future where we don’t build complex query + reranking pipeline. Instead, agents orchestrate simpler retrieval primitives. A basic keyword search or embedding model with a few filters. Basic, scalable, and simple retrieval tools.
Then we deploy an agentic search model like SID-1. It knows what’s relevant in our domain. It gets our users. Now it can orchestrate the tools to find relevant search results. Currently, sure, the focus begins with RAG and classic passage retrieval (i.e. chunks). That will surely expand to a family of models, targeting different domains from e-commerce to job search to ??.
Today we have scores of embedding models on huggingface, targeting financial, legal, e-commerce. Why wouldn’t we also have many agentic search models? Tuned to domains?
An embedding only solves a narrow portion of the problem (similarity). An agentic search model could encompass the entire process from query understanding to hybrid search. Yes they’re too slow today to drive site search. But that will surely change in the years ahead.
It’s a future I’m excited about. Search will look radically different.
If you want to learn about these topics, check out my Cheat at Search w/ Agents class starting Monday.
Upcoming events: Vectors Week

Join me for Vectors Week, a series of events about vector retrieval, hybrid search, and building your own vector database.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky