BM25 models the odds a term would be observed in a relevant document (vs the term occurring in an irrelevant doc).
It’s based on probabilistic relevance, capturing:
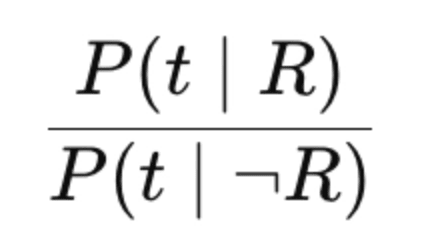
- t - a query term match occurs
- R - the doc is relevant
Queries of course contain multiple terms. How do we combine those odds? The odds of BOTH terms being in a relevant doc, we’d need to multiply Odds(t1) * Odds(t2).
If we take the log of these multiplied odds, we can take advantage of a property of logarithms: log(Odds(t1) * Odds(t2)) = log(Odds(t1)) + log(Odds(t2)). Or taken together across each term:
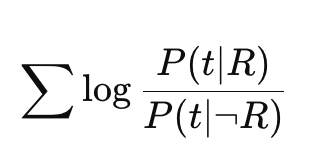
BM25 tries to model this!
How?
We can imagine cases where a term match would occur in a relevant doc (the numerator). Why might a term match occur an in an irrelevant doc?
- The term’s ambiguous, not specific to the user’s intent.
luke skywalker- luke occurs all over the place. It’s common. The rare termskywalkeroccurs only in only Star Wars → thats how we get Inverse Document Frequency. - The document is not ABOUT that term - A term occurring spuriously (low term frequency) would not mean the document is relevant. Or a term not being a large enough proportion of the text: Skywalker being mentioned a few times in a book length tome may just happen accidentally.
Through trial, error, and experimentation with open datasets we arrived at the exact BM25 formula.
That’s how we get a BM25 that’s probabilistic, but not a probability
My AI Powered Search training with Trey Grainger starts THURSDAY - signup here
-Doug
This is part of Doug’s Daily Search tips - subscribe here
Upcoming course: Build your own vector database

Want to understand what makes embedding retrieval fast, relevant, and useful in real AI systems? Join Build your own vector database and build the core pieces yourself, from embeddings and indexing to search and retrieval.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky