Agents don’t reason, they do research.
Research means evaluating evidence to understand the correct state of the world. This goes beyond “searching with ChatGPT”. Research is behind a lot of what we want agents to do. Claude Code researches for you when writing code. Your value is a human is steering this research, compensating for the LLMs deficiencies and naiveté.
We all know agents can be sycophantic. In just wanting to please you they can be poor researchers, falling prey to confirmation bias. They can be prone to rabbit holes - focusing only on some particular trees, rather than the forest. They solve exactly the problem you ask them to. They don’t tell you that you’re solving the wrong problem (after all recieving such a critique might make you grumpy!).
Agents don’t often evaluate the trustworthiness of sources. They struggle to differentiate between content that’s authoritative, biased, or just maybe some weird blog post written by a weirdo like me. When agents go down into complex reasoning they stretch their context considerably. They forget details mentioned earlier like “check for confirmation on this source” and decide instead to plow forward. They can thrash in weird parts of the problem that don’t make sense to us. Whether they’re doing a good job in reasoning about research can be very domain specific - scientific research, technical documentation, blog posts, all need to be thought of through a different lens, depending on your task and domain.
Yet unlike humans, they lack ego. They don’t have much tolerance for cognitive dissonance. They will reevaluate when you point out inconsistent information and — so long as it has enough context to remember — they will create a new mental model of the facts. Unlike humans which hold on to wrong facts till the bitter end. In this way, they can — if prompted correctly — become a kind of egoless research notebook of internally consistent state.
And of course, none of this works without good search. Which is why you should come to one of my Maven courses 😊. But as I’m also technically a published historian, I thought it’d be fun to step away from search for a bit, and see more deeply that when we say “agent” we more and more mean “researcher”.
LLMs tell you what you want to hear
Not even trying to be sycophantic, its pleasing to get an affirmative to your answer. And LLMs do this in spades. This also leads to solving the wrong problem - whether research or coding - by focusing just on this narrow set of trees rather than the bigger picture.
As an example, I noticed similarities between two shows recently - The Critic and Family Guy. The Critic precedes Family Guy, so I asked ChatGPT what I thought was a simple question.

It may not seem like a leading question, but clearly ChatGPT wants to make the case in the affirmative. But if I ask a more balanced question, I get a different story:

And if I scroll down to reasons AGAINST, I get information contradictory from the above

The other thing that jumps out to me - The LLM did not search and reason about what it found, so I cannot easily evaluate its evidence or “thought” process
So let me adjust the prompt to better consider the evidence for and against.
LLMs don’t always do a good job evaluating evidence
When I adjust the prompt to search and consider evidence, I get GPT-5s long reasoning. Which is (good?) I hope and can give me more to evaluate.
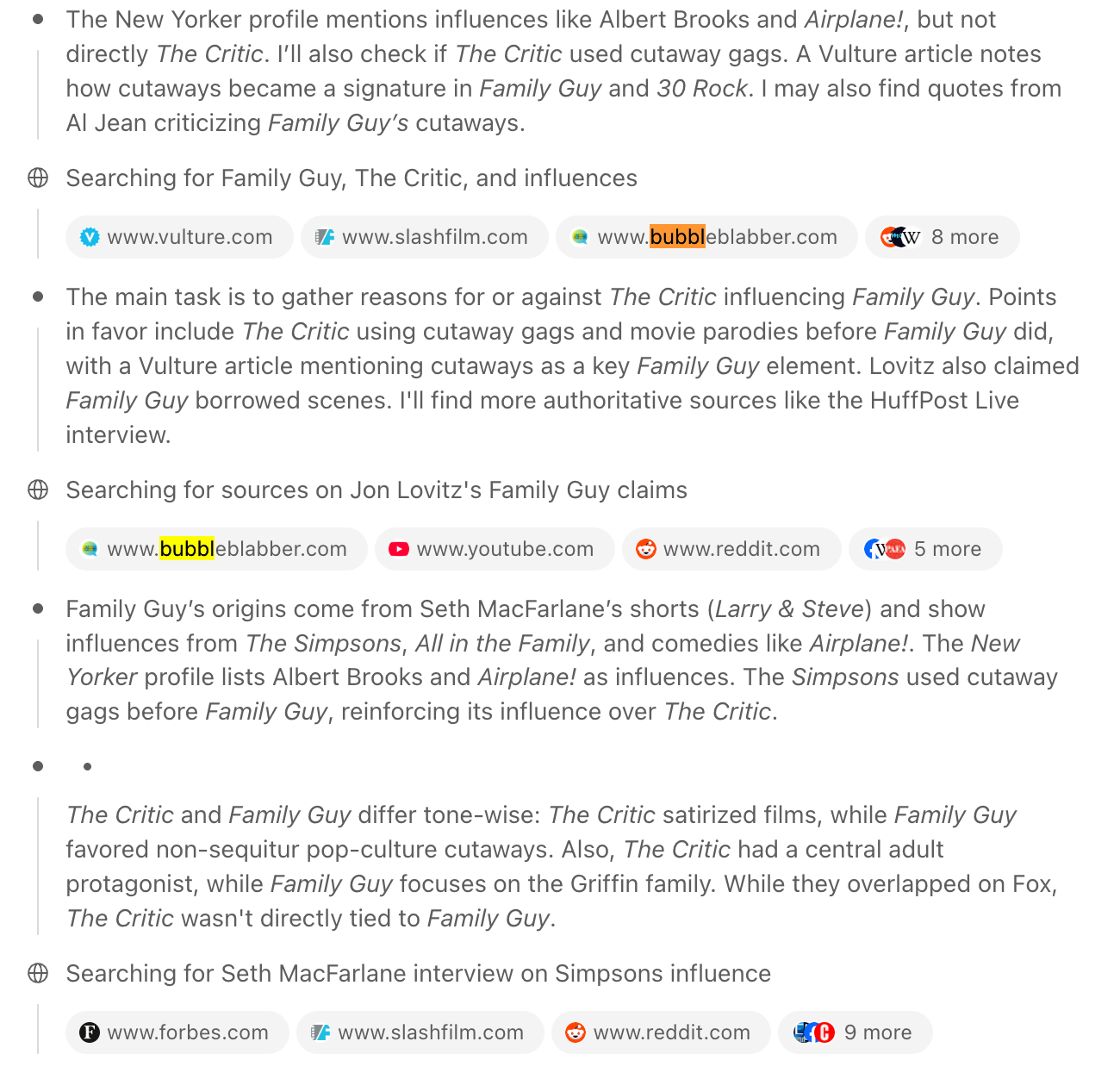
And I get back a response with a mix of for / against grounded in research.
Yet one that jumps out as sketchy is this 12 year old post from BubbleBlabber which GPT5 takes at face value. Here’s one of the top level “pros” bullets.
Contemporaries said so: Jon Lovitz (Jay Sherman) once claimed on HuffPost Live that Family Guy had “borrowed scenes” from The Critic (reported at the time by Bubbleblabber). It’s an allegation, but it shows the perception of influence from people involved with The Critic.
So one time, Jon Lovitz (the main actor in The Critic), said something on HuffPost Live. GPT-5 first:
- Calls a one-off forum post “reporting”
- Cites the forum post, not the primary source
- Doesn’t point out its 12 years old
- Doesn’t double-check the information
- Doesn’t consider other things Jon Lovitz may have said about Family Guy
On the positive side, GPT 5 correctly points out this is just an allegation.
This research has tremendous value but it requires you, the human, to think critically about the cited information. I’m not arguing the facts that Jon Lovitz said something, but there’s a bigger picture. Maybe Jon Lovitz has also said positive things about Family Guy? Maybe we don’t have the full context of what Lovitz said? Maybe the LLM was trying to give too “balanced” of a perspective in giving For / Against - a kind of “both sides” bias.
Now consider if you’re asking Claude Code to search the Web, then take an action for you. This need for critical thinking about the evidence it uses can be doubly true. You the human, have the ultimate responsibility.
The agent forgot to double check?
Looking at the agents reasoning is crucial. We can see what GPT-5 considered when evaluating the evidence.
- The forum post quoting Jon Lovitz was taken at face value
- An attempt to find “more authoritative sources like the HuffPost Live interview”. Maybe that’s an attempt to double check the Jon Lovitz quote, but it may have forgotten
Was the agent thrashing on one weird topic?
In these sorts of research situations, we often need to look at the direction the agent was going down. Did it get stuck in a weird rabbit hole in its reasoning? For example, when I look into the focus on “cutaway gags”. This is a signature of the comedy of The Critic and Family Guy, but we might question whether so much focus should be spent on this topic vs direct quotes from creators.

Perhaps, with our domain expertise, we might say this is perfectly fine rabbit hole. Or we may - as is often the case with Claude Code - abort the reasoning if it seems to go off into a weird direction.
Redirecting the LLM to solve internal cognitive dissonance
When you find something fishy in some research, you can point out internal inconsistencies or perhaps emphasize issues with the evidence the LLM did not consider. The LLM will correct itself. So here we’ll ask the LLM to focus on quotes from The Critic creators specifically, while also pointing out the one bit of strange evidence.
But again, its important to ask something not even close to leading. You need to give it an opportunity to consider BOTH pros and cons. So I sent the following prompt
You cited a “Bubbleblather” article which seems a bit sketchy. Even if it points to old HuffPost Live.
Can you look into other people involved in The Critic to corroborate what Jon Lovitz said? Did others involved in The Critic have this impression of Family Guy
It’s important you give pros/cons. Cases where people involved in The Critic did not believe Family Guy “ripped off” and others perhaps where they consider Family Guy borrowing (even stealing) ideas from The Family Guy
It feels like this gives a more complete picture of how people from The Critic actually feel about Family Guy to understand their feelings on the matter.

I like that I’m getting direct sources. I have a higher degree of trust for Wikipedia, Vulture, Slashfilm. I may want to look into the Reddit AMA more directly to consider the context. I don’t know what TheaterMania is, but I might look into that a bit more critically.
Summing up
I was doing this research for fun, but imagine if I was doing this for work? Or relied on code generated by coding research?
So far in my research journey I’ve uncovered
- Strong confirmation bias – not even being sycophantic per-se, the LLM wanted to confim my question
- Poor consideration of sources. I’ve had to double check and carefully consider their quality
- Perhaps forgetting something it mentioned in reasoning (about the Lovitz quote not being reputable)
- An ability to be critiqued and questioned that improved the research (hey double check your conclusion on the Lovitz quote)
And I haven’t even considered domain expertise here. What if this was science? Or I was building a legal case?
If you absolutely care about quality research, using an LLM is not as straightforward as just asking a simple question. You need to work against your ego’s need for confirmation, but with the egolessness of the LLM.
Upcoming course: Build your own vector database

Want to understand what makes embedding retrieval fast, relevant, and useful in real AI systems? Join Build your own vector database and build the core pieces yourself, from embeddings and indexing to search and retrieval.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky