When I’ve wanted to play with Elasticsearch from a Jupyter notebook in the past, I’ve had to wrestle with complicated local setups - Docker containers and Python dependency hell. Especially when I’ve had to install the normal Python data science stack (numpy / pandas / sklearn, etc) , I can just end up pulling my hair out.
In this article, I want to sidestep those headaches with the cloud magic of Colab and Bonsai…
Bonsai is a hosting provider for Elasticsearch providing hosting for companies like AT&T and OfferUp. I’ve worked with their team in the past on difficult search projects, and always been impressed by their skill and professionalism.
It turns out, Bonsai’s free tier makes a great sandbox for experimenting with search from a Google Collab notebook environment. I plan to use this for my upcoming ML Powered Search Relevance Coruse. Let’s walk through quickly how to set this up if you want to play with Elasticsearch from a notebook!
Once you create an account, you select “create a free sandbox cluster” on Bonsai
Things will take a few seconds to spin up…
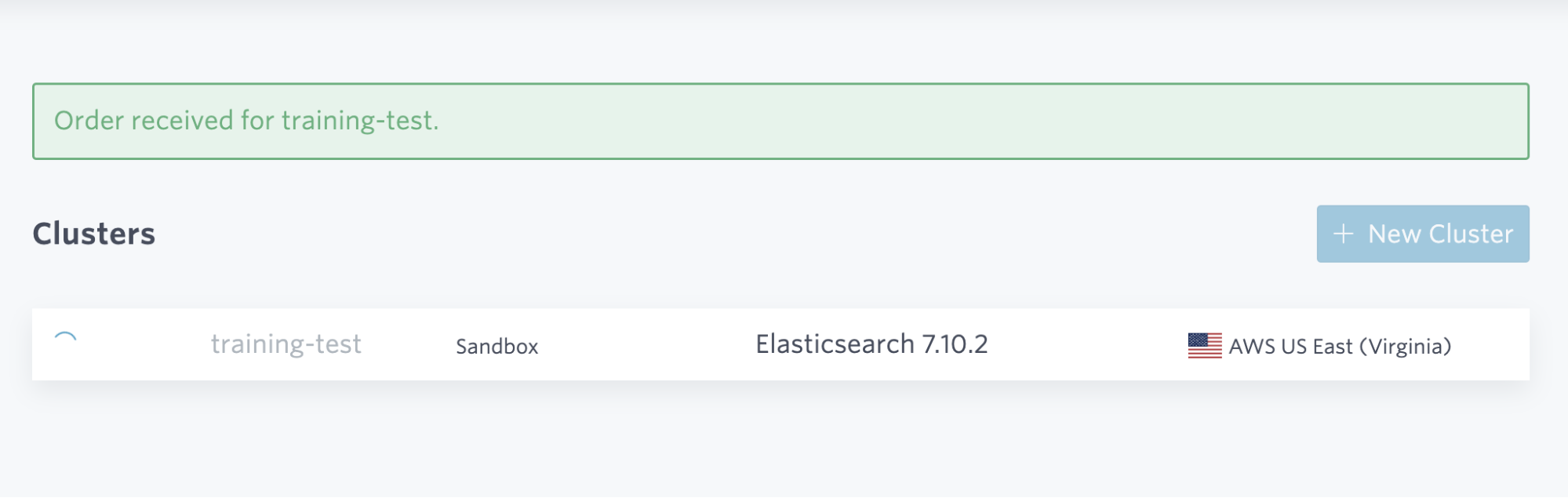
Once provisioned, you can click into the admin for your cluster. Notice you can find the tools you’re used to with Elasticsearch - kibana, etc.
For our purposes, we want to go to Access -> Credentials and grab the Full Access URL.
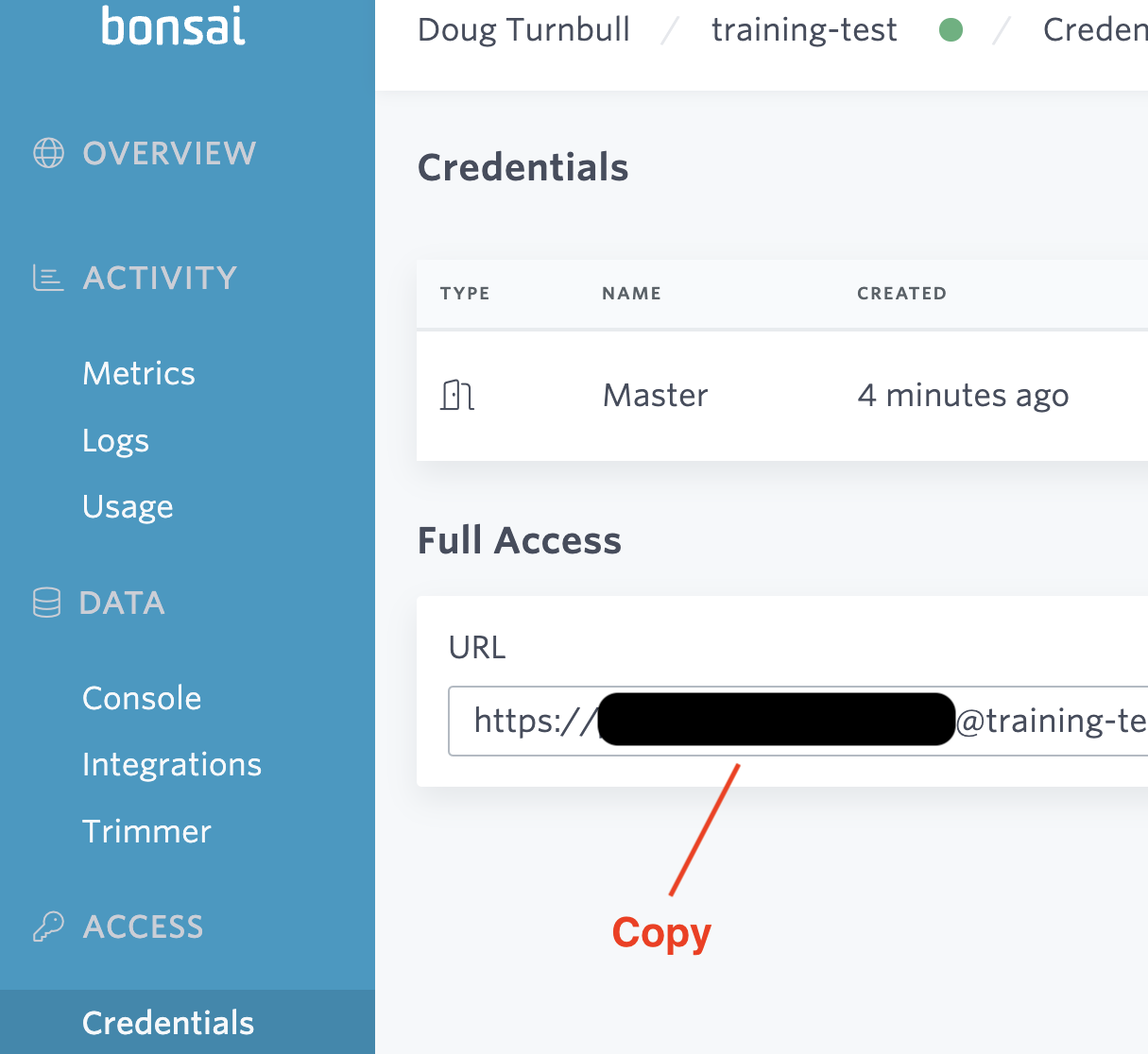
I’ve hidden my credentials for good measure. But its important to treat this just as a sandbox. For throw away test data that you don’t care about past your temporary experiments. It’s important to add the document limit on Bonsai’s sandbox is 30k docs. Just enough to play around.
Now let’s go to Collab…
Here I’m going to index and search the data from the retrotech dataset from AI Powered Search. You can see the final notebook here in colab.
Go to Google Colab and create a new notebook.
In the first cell paste in the following code…
!pip install elasticsearch==7.10.1
![ ! -d 'retrotech' ] && git clone https://github.com/ai-powered-search/retrotech.git
! cd retrotech && git pull
! cd retrotech && tar -xvf products.tgz && tar -xvf signals.tgz
(Change the Elasticsearch version to whatever’s compatible with your cluster version)
Ok from now on, I’ll just paste in code…
Next we paste some code to prompt us for the Elasticsearch URL you copied from Bonsai above… It’s a bit more secure than just letting the URL hang out in the notebook source itself.
import getpass
es_url = getpass.getpass("Paste in your Elasticsearch URL")
Once you run this and paste in your Elasticsearch URL, you can setup an Elasticsearch Python client. Your ping should succeed…
from elasticsearch import Elasticsearch
es = Elasticsearch(es_url)
es.ping()
Next we index the retrotech dataset…
import csv
from elasticsearch.helpers import bulk
from elasticsearch import RequestError
def retrotech_data():
with open('retrotech/products.csv') as csv_file:
products_reader = csv.DictReader(csv_file)
for row in products_reader:
yield {
'_source': row,
'_index': 'retrotech',
'_id': row['upc']
}
try:
es.indices.create('retrotech')
bulk(es, retrotech_data())
except RequestError:
print("Not recreating index that already exists")
And finally, we search!
hits = es.search(index='retrotech', body={'query': {'match': {'name': 'transformers'}}})
hits = hits['hits']['hits']
for hit in hits:
print(hit['_source']['name'])
Now you should be able to do whatever you like with this Elasticsearch cluster. Experiment with different relevance ideas, making this index smarter / give more relevant results, or whatever else you might want to for your use case.
Finally, when you’ve done your work, because its a sandbox cluster, it’s not a bad idea to clean up…
es.indices.delete('retrotech')
That’s it! Have fun. And if you want to learn how to build smart, relevant search systems - find me at my ML Powered Search course!
Enjoy softwaredoug in training course form!
Starting May 18!
Signup here - http://maven.com/softwaredoug/cheat-at-search I hope you join me at Cheat at Search with Agents to learn use agents in search. build better RAG and use LLMs in query understanding.
I hope you join me at Cheat at Search with Agents to learn use agents in search. build better RAG and use LLMs in query understanding.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky